Do you use between to return data that has dates? Do you know that between will get everything since midnight from the first criteria and up to midnight exactly from the second criteria. If you do BETWEEN 2006-10-01 AND 2006-10-02 then all the values that are greater or equal than 2006-10-01 and less or equal to 2006-10-02 will be returned. So no values after 2006-10-02 midnight will be returned.
Let's test this out, first let's create this table
CREATE TABLE SomeDates (DateColumn DATETIME)
Insert 2 values
INSERT INTO SomeDates VALUES('2006-10-02 00:00:00.000')
INSERT INTO SomeDates VALUES('2006-10-01 00:00:00.000')
Return everything between '2006-10-01' and '2006-10-02'
SELECT *
FROM SomeDates
WHERE DateColumn BETWEEN '20061001' AND '20061002'
ORDER BY DateColumn
This works without a problem
Let's add some more dates including the time portion
INSERT INTO SomeDates VALUES('2006-10-02 00:01:00.000')
INSERT INTO SomeDates VALUES('2006-10-02 00:00:59.000')
INSERT INTO SomeDates VALUES('2006-10-02 00:00:01.000')
INSERT INTO SomeDates VALUES('2006-10-01 00:01:00.000')
INSERT INTO SomeDates VALUES('2006-10-01 00:12:00.000')
INSERT INTO SomeDates VALUES('2006-10-01 23:00:00.000')
Return everything between '2006-10-01' and '2006-10-02'
SELECT *
FROM SomeDates
WHERE DateColumn BETWEEN '20061001' AND '20061002'
ORDER BY DateColumn
Here is where it goes wrong; for 2006-10-02 only the midnight value is returned the other ones are ignored
Now if we change 2006-10-02 to 2006-10-03 we get what we want
SELECT *
FROM SomeDates
WHERE DateColumn BETWEEN '20061001' AND '20061003'
ORDER BY DateColumn
Now insert a value for 2006-10-03 (midnight)
INSERT INTO SomeDates VALUES('2006-10-03 00:00:00.000')
Run the query again
SELECT *
FROM SomeDates
WHERE DateColumn BETWEEN '20061001' AND '20061003'
ORDER BY DateColumn
We get back 2006-10-03 00:00:00.000; between will return the date if it is exactly midnight
If you use >= and < then you get exactly what you need
SELECT *
FROM SomeDates
WHERE DateColumn >= '20061001' AND DateColumn < '20061003'
ORDER BY DateColumn
--Clean up
DROP TABLE SomeDates
So be careful when using between because you might get back rows that you did not expect to get back and it might mess up your reporting if you do counts or sums
Monday, October 23, 2006
Sunday, October 22, 2006
SQL Server 2005 Practical Troubleshooting: The Database Engine Sample Chapter Available
Ken Henderson has posted a sample chapter from the forthcoming book SQL Server 2005 Practical Troubleshooting: The Database Engine on his blog. The sample chapter is: Chapter 4 Procedure Cache Issues. This is a must read for anyone who is troubleshooting SQL Server queries and procedures. Some of the things covered are: Cached Object Leaks, Cursor Leaks, Parameter Sniffing, Excessive Compilation, Poor Plan Reuse and How Cache Lookups Work. I think that this is the first time I have seen parameter sniffing described in a book. Check it out and let me know what you think.
SQLQueryStress Beta 1 Available For Download
Adam Machanic has made available beta 1 of the SQLQueryStress tool. It provides some support for query parameterization and options for collection of I/O and CPU metrics. It is not intended to replace tools such as Visual Studio Team System's load tests, but rather to be a simple and easy-to-use tool in the DBA or database developer's kit.
To download the tool and read the documentation go here: http://www.datamanipulation.net/SQLQueryStress/
To download the tool and read the documentation go here: http://www.datamanipulation.net/SQLQueryStress/
Wednesday, October 18, 2006
Visual Studio Team Edition for Database Professionals CTP 6 Is Available For Download
Gert Drapers has announced that CTP6 of Visual Studio Team Edition for Database Professionals is available for download
This is an overview of the highlights in CTP6
This is an overview of the highlights in CTP6
- Full support for SQL Server 2000 & 2005 objects, the parser work has been completed
- Extended Properties support, we know import and deploy all your extended properties
- Inline constraint support, if you do not want to separate them out, we allow them inline as well
- Pre- and post deployment scripts population during Import Script
- Full support for command line build & deploy and Team Build
- A new Import Schema Wizard which is also integrated with the New Project Wizard to make project creation and import a single stop shop
- Synchronize your database project from Schema Compare, compare your project with a database and pull the differences in to the database project
- Schema refactoring is now allowed even if you have files in a warning state
- Resolve 3 and 4 part name usage when the referenced database is locally present, same for linked servers
- The product no longer installs SQL Express; you can pick your own SQL Server 2005 Developer Edition or SQL Server 2005 Enterprise Edition instance on the local box. When you first start the product for the first time we will ask you to choose an local instance to use
- Display detailed Schema Object properties in the VS Property Window for selected objects in the Schema View
- Separation of user target database settings through user project files, this allows users to work against a different target instance without changing the main project file.
- We made great progress on the overall stability and performance of the product across the board, project creation, importing your schema, reloading project and making changes to your schema
- And last but not least we fixed many reported customer problems!
Visit The Data Dude blog for more info
Monday, October 16, 2006
SQL Server Database Publishing Wizard CTP 1 released
SQL Server Hosting Toolkit Released
The goal of the SQL Server Hosting Toolkit is to enable a great experience around SQL Server in shared hosting environments.
The toolkit will eventually consist of a suite of tools and services that hosters can deploy for use by their customers. It will also serve as an incubation vehicle for tools that hosting customers can download and use directly, regardless of whether their hoster has deployed the toolkit
Database Publishing Wizard Community Technology Preview 1
The Database Publishing Wizard enables the deployment of SQL Server 2005 databases into a hosted environment on either a SQL Server 2000 or 2005 server. It generates a SQL script file which can be used to recreate the database in shared hosting environments where the only connectivity to a server is through a web-based control panel with a scripting window.
The goal of the SQL Server Hosting Toolkit is to enable a great experience around SQL Server in shared hosting environments.
The toolkit will eventually consist of a suite of tools and services that hosters can deploy for use by their customers. It will also serve as an incubation vehicle for tools that hosting customers can download and use directly, regardless of whether their hoster has deployed the toolkit
Database Publishing Wizard Community Technology Preview 1
The Database Publishing Wizard enables the deployment of SQL Server 2005 databases into a hosted environment on either a SQL Server 2000 or 2005 server. It generates a SQL script file which can be used to recreate the database in shared hosting environments where the only connectivity to a server is through a web-based control panel with a scripting window.
Scrum
I am having Scrum training tomorrow. So what is Scrum anyway?
Scrum is an agile method for project management. Scrum was named as a project management style in auto and consumer product manufacturing companies by Takeuchi and Nonaka in "The New New Product Development Game" (Harvard Business Review, Jan-Feb 1986). They noted that projects using small, cross-functional teams historically produce the best results, and likened these high-performing teams to the scrum formation in Rugby. Jeff Sutherland, John Scumniotales, and Jeff McKenna documented, conceived and implemented Scrum as it is described below at Easel Corporation in 1993, incorporating team management styles noted by Takeuchi and Nonaka. In 1995, Ken Schwaber formalized the definition of Scrum and helped deploy it worldwide in software development.
Its intended use is for management of software development projects, and it has been successfully used to "wrap" Extreme Programming and other development methodologies. However, it can theoretically be applied to any context where a group of people need to work together to achieve a common goal - such as setting up a small school, scientific research projects or planning a wedding.
Although Scrum was intended to be for management of software development projects, it can be used in running maintenance teams, or as a program management approach: Scrum of Scrums.
Characteristics of Scrum
A living backlog of prioritized work to be done;
Completion of a largely fixed set of backlog items in a series of short iterations or sprints;
A brief daily meeting or scrum, at which progress is explained, upcoming work is described and impediments are raised.
A brief planning session in which the backlog items for the sprint will be defined.
A brief heartbeat retrospective, at which all team members reflect about the past sprint.
Scrum is facilitated by a ScrumMaster, whose primary job is to remove impediments to the ability of the team to deliver the sprint goal. The ScrumMaster is not the leader of the team (as they are self-organising) but acts as a productivity buffer between the team and any destabilising influences.
Scrum enables the creation of self-organising teams by encouraging verbal communication across all team members and across all disciplines that are involved in the project.
A key principle of Scrum is its recognition that fundamentally empirical challenges cannot be addressed successfully in a traditional "process control" manner. As such, Scrum adopts an empirical approach - accepting that the problem cannot be fully understood or defined, focusing instead on maximizing the team's ability to respond in an agile manner to emerging challenges.
Notably missing from Scrum is the "cookbook" approach to project management exemplified in the Project Management Body of Knowledge or Prince2 - both of which have as their goal quality through application of a series of prescribed processes.
This is what the training will cover tomorrow
Creating An Agile Environment (An introduction to Scrum)
Presentation Outline:
I. Definition of Agile
II. Agile Principles and Values
III. Historical Background in Software Development
IV. Overview of Scrum
V. Roles and Responsibilities
VI. Benefits and Challenges in using Scrum
VII. Agile adoption patterns for large organizations
VIII. Questions and Recommended Reading
What is Scrum? Scrum is an iterative, incremental process for developing any product or managing any work. It produces a potentially shippable set of functionality at the end of every iteration. It's attributes are:
So my question to you is, do you use Scrum? And if you do then did it improve the process of development? We do use it actually but the developers did not get training yet.
Scrum is an agile method for project management. Scrum was named as a project management style in auto and consumer product manufacturing companies by Takeuchi and Nonaka in "The New New Product Development Game" (Harvard Business Review, Jan-Feb 1986). They noted that projects using small, cross-functional teams historically produce the best results, and likened these high-performing teams to the scrum formation in Rugby. Jeff Sutherland, John Scumniotales, and Jeff McKenna documented, conceived and implemented Scrum as it is described below at Easel Corporation in 1993, incorporating team management styles noted by Takeuchi and Nonaka. In 1995, Ken Schwaber formalized the definition of Scrum and helped deploy it worldwide in software development.
Its intended use is for management of software development projects, and it has been successfully used to "wrap" Extreme Programming and other development methodologies. However, it can theoretically be applied to any context where a group of people need to work together to achieve a common goal - such as setting up a small school, scientific research projects or planning a wedding.
Although Scrum was intended to be for management of software development projects, it can be used in running maintenance teams, or as a program management approach: Scrum of Scrums.
Characteristics of Scrum
A living backlog of prioritized work to be done;
Completion of a largely fixed set of backlog items in a series of short iterations or sprints;
A brief daily meeting or scrum, at which progress is explained, upcoming work is described and impediments are raised.
A brief planning session in which the backlog items for the sprint will be defined.
A brief heartbeat retrospective, at which all team members reflect about the past sprint.
Scrum is facilitated by a ScrumMaster, whose primary job is to remove impediments to the ability of the team to deliver the sprint goal. The ScrumMaster is not the leader of the team (as they are self-organising) but acts as a productivity buffer between the team and any destabilising influences.
Scrum enables the creation of self-organising teams by encouraging verbal communication across all team members and across all disciplines that are involved in the project.
A key principle of Scrum is its recognition that fundamentally empirical challenges cannot be addressed successfully in a traditional "process control" manner. As such, Scrum adopts an empirical approach - accepting that the problem cannot be fully understood or defined, focusing instead on maximizing the team's ability to respond in an agile manner to emerging challenges.
Notably missing from Scrum is the "cookbook" approach to project management exemplified in the Project Management Body of Knowledge or Prince2 - both of which have as their goal quality through application of a series of prescribed processes.
This is what the training will cover tomorrow
Creating An Agile Environment (An introduction to Scrum)
Presentation Outline:
I. Definition of Agile
II. Agile Principles and Values
III. Historical Background in Software Development
IV. Overview of Scrum
V. Roles and Responsibilities
VI. Benefits and Challenges in using Scrum
VII. Agile adoption patterns for large organizations
VIII. Questions and Recommended Reading
What is Scrum? Scrum is an iterative, incremental process for developing any product or managing any work. It produces a potentially shippable set of functionality at the end of every iteration. It's attributes are:
- Scrum is an agile process to manage and control development work.
- Scrum is a wrapper for existing engineering practices.
- Scrum is a team-based approach to iteratively, incrementally develop systems and products when requirements are rapidly changing
- Scrum is a process that controls the chaos of conflicting interests and needs.
- Scrum is a way to improve communications and maximize co-operation.
- Scrum is a way to detect and cause the removal of anything that gets in the way of developing and delivering products.
- Scrum is scalable from single projects to entire organizations. Scrum has controlled and organized development and implementation for multiple interrelated products and projects with over a thousand developers and implementers.
- Scrum is a way for everyone to feel good about their job, their contributions, and that they have done the very best they possibly could.
So my question to you is, do you use Scrum? And if you do then did it improve the process of development? We do use it actually but the developers did not get training yet.
Hello OUTPUT See You Later Trigger Or Perhaps Not?
SQL Server 2005 has added an optional OUTPUT clause to UPDATE, INSERT and DELETE commands, this enables you to accomplish almost the same task as if you would have used a after trigger in SQL Server 2000
Let's take a closer look, let's start with the syntax
The syntax for an insert is like this
INSERT INTO TableNAme
OUTPUT Inserted
VALUES (....)
The syntax for an update is like this
UPDATE TableNAme
SET ......
OUTPUT Deleted,Inserted
WHERE ....
The syntax for a delete is like this
DELETE TableName
OUTPUT Deleted
WHERE ....
So the OUTPUT comes right before the WHERE or the VALUES part of the statement
Also as you can see Insert has Inserted as part of the OUTPUT Clause, Update has Inserted and Deleted and Delete has Deleted as part of the OUTPUT Clause, this is very simmilar to the inserted and deleted pseudo-tables in triggers
Let's test it out, first we have to create a table
CREATE TABLE TestOutput
(
ID INT NOT NULL,
Description VARCHAR(50) NOT NULL,
)
INSERT INTO TestOutput (ID, Description) VALUES (1, 'Desc1')
INSERT INTO TestOutput (ID, Description) VALUES (2, 'Desc2')
INSERT INTO TestOutput (ID, Description) VALUES (3, 'Desc3')
Let's show what we just inserted
INSERT INTO TestOutput (ID, Description)
OUTPUT Inserted.ID AS ID,Inserted.Description AS Description
VALUES (4, 'Desc4')
The * wildcard works also in this case
INSERT INTO TestOutput (ID, Description)
OUTPUT Inserted.*
VALUES (5, 'Desc5')
Let's try it with a delete statement
DELETE TestOutput
OUTPUT Deleted.*
WHERE ID = 4
Let's try to use Inserted here
DELETE TestOutput
OUTPUT Inserted.*
WHERE ID = 4
The message that is returned is this
Server: Msg 107, Level 15, State 1, Line 1
The column prefix 'Inserted' does not match with a table name or alias name used in the query.
So as you can see Inserted can not be used with a DELETE command
Let's try using deleted with an insert command
INSERT INTO TestOutput (ID, Description)
OUTPUT Deleted.*
VALUES (5, 'Desc5')
Same story, Deleted can not be used with an INSERT command
Server: Msg 107, Level 15, State 1, Line 1
The column prefix 'Deleted' does not match with a table name or alias name used in the query.
Let's take a look at the update statement
UPDATE TestOutput
SET ID = 4
OUTPUT DELETED.ID AS OldId, DELETED.Description AS oldDescription ,
Inserted.ID AS New_ID , Inserted.Description AS Newdescription
WHERE ID = 5
Create a table where we will insert our output results into
CREATE TABLE #hist (OldID INT,OldDesc VARCHAR(50),
New_ID INT,NewDesc VARCHAR(50),UpdatedTime DATETIME)
Let's insert the old and new values into a temp table (audit trail..kind of)
UPDATE TestOutput
SET ID = 666
OUTPUT DELETED.ID AS OldId, DELETED.Description AS oldDescription ,
Inserted.ID AS New_ID , Inserted.Description AS Newdescription,GETDATE() INTO #hist
WHERE ID = 3
let's see what we inserted
SELECT * FROM #hist
Remember this message?
Server: Msg 512, Level 16, State 1, Line 2
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
You would get this in a trigger when a trigger would fire after a multi row statement and you tried to assign a value to a variable. Since you can't assign values to variable with the OUTPUT clause you won't have this problem
How does identity work with the output clause?
CREATE TABLE TestOutput2
(
ID INT NOT NULL IDENTITY,
Description VARCHAR(50) NOT NULL,
)
INSERT INTO TestOutput2 (Description)
OUTPUT Inserted.*
SELECT 'Desc1' UNION ALL
SELECT 'Desc2'
We can not use SCOPE_IDENTITY() or @@IDENTITY, the value for those will both be 2, run the following example to see this
INSERT INTO TestOutput2 (Description)
OUTPUT SCOPE_IDENTITY(),@@IDENTITY,Inserted.*
SELECT 'Desc3' UNION ALL
SELECT 'Desc4'
The bottom line.
The OUTPUT clause is very useful but I don't think it's a replacement for triggers. A trigger can protect your table for any user (unless you execute a alter table..disable trigger statement)
If you use OUTPUT exclusively, then if someone uses a tool like Enterprise Manager to insert a row into your table there is nothing to fire if you want to create an audit trail for example
So it has it's uses but won't replace the trigger
Let's take a closer look, let's start with the syntax
The syntax for an insert is like this
INSERT INTO TableNAme
OUTPUT Inserted
VALUES (....)
The syntax for an update is like this
UPDATE TableNAme
SET ......
OUTPUT Deleted,Inserted
WHERE ....
The syntax for a delete is like this
DELETE TableName
OUTPUT Deleted
WHERE ....
So the OUTPUT comes right before the WHERE or the VALUES part of the statement
Also as you can see Insert has Inserted as part of the OUTPUT Clause, Update has Inserted and Deleted and Delete has Deleted as part of the OUTPUT Clause, this is very simmilar to the inserted and deleted pseudo-tables in triggers
Let's test it out, first we have to create a table
CREATE TABLE TestOutput
(
ID INT NOT NULL,
Description VARCHAR(50) NOT NULL,
)
INSERT INTO TestOutput (ID, Description) VALUES (1, 'Desc1')
INSERT INTO TestOutput (ID, Description) VALUES (2, 'Desc2')
INSERT INTO TestOutput (ID, Description) VALUES (3, 'Desc3')
Let's show what we just inserted
INSERT INTO TestOutput (ID, Description)
OUTPUT Inserted.ID AS ID,Inserted.Description AS Description
VALUES (4, 'Desc4')
The * wildcard works also in this case
INSERT INTO TestOutput (ID, Description)
OUTPUT Inserted.*
VALUES (5, 'Desc5')
Let's try it with a delete statement
DELETE TestOutput
OUTPUT Deleted.*
WHERE ID = 4
Let's try to use Inserted here
DELETE TestOutput
OUTPUT Inserted.*
WHERE ID = 4
The message that is returned is this
Server: Msg 107, Level 15, State 1, Line 1
The column prefix 'Inserted' does not match with a table name or alias name used in the query.
So as you can see Inserted can not be used with a DELETE command
Let's try using deleted with an insert command
INSERT INTO TestOutput (ID, Description)
OUTPUT Deleted.*
VALUES (5, 'Desc5')
Same story, Deleted can not be used with an INSERT command
Server: Msg 107, Level 15, State 1, Line 1
The column prefix 'Deleted' does not match with a table name or alias name used in the query.
Let's take a look at the update statement
UPDATE TestOutput
SET ID = 4
OUTPUT DELETED.ID AS OldId, DELETED.Description AS oldDescription ,
Inserted.ID AS New_ID , Inserted.Description AS Newdescription
WHERE ID = 5
Create a table where we will insert our output results into
CREATE TABLE #hist (OldID INT,OldDesc VARCHAR(50),
New_ID INT,NewDesc VARCHAR(50),UpdatedTime DATETIME)
Let's insert the old and new values into a temp table (audit trail..kind of)
UPDATE TestOutput
SET ID = 666
OUTPUT DELETED.ID AS OldId, DELETED.Description AS oldDescription ,
Inserted.ID AS New_ID , Inserted.Description AS Newdescription,GETDATE() INTO #hist
WHERE ID = 3
let's see what we inserted
SELECT * FROM #hist
Remember this message?
Server: Msg 512, Level 16, State 1, Line 2
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
You would get this in a trigger when a trigger would fire after a multi row statement and you tried to assign a value to a variable. Since you can't assign values to variable with the OUTPUT clause you won't have this problem
How does identity work with the output clause?
CREATE TABLE TestOutput2
(
ID INT NOT NULL IDENTITY,
Description VARCHAR(50) NOT NULL,
)
INSERT INTO TestOutput2 (Description)
OUTPUT Inserted.*
SELECT 'Desc1' UNION ALL
SELECT 'Desc2'
We can not use SCOPE_IDENTITY() or @@IDENTITY, the value for those will both be 2, run the following example to see this
INSERT INTO TestOutput2 (Description)
OUTPUT SCOPE_IDENTITY(),@@IDENTITY,Inserted.*
SELECT 'Desc3' UNION ALL
SELECT 'Desc4'
The bottom line.
The OUTPUT clause is very useful but I don't think it's a replacement for triggers. A trigger can protect your table for any user (unless you execute a alter table..disable trigger statement)
If you use OUTPUT exclusively, then if someone uses a tool like Enterprise Manager to insert a row into your table there is nothing to fire if you want to create an audit trail for example
So it has it's uses but won't replace the trigger
Sunday, October 15, 2006
Saving A DTS Package On Another Server
How do I save a DTS package on another server? I have answered this question so many times in the past year or so that I decided to write a little post about it.
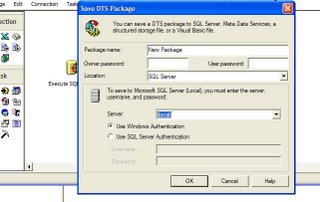
First way: Just save it on the other server
From the location dropdown select SQL server, enter the IP or sever name and supply the credentials and you are done. click on the image below this text to see a larger image
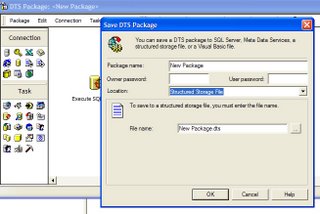
Second way: Save the package as a Structured Storage File
Most of the times you won't be able to save the file directly on the destination server. The server might be in a DMZ and behind a couple of firewalls. In that case you can save the package as a Structured Storage File. From the dropdown select Structured Storage File (see picture below) Give the file a name and save it in a folder. You probably won't be able to save the file on the destination server, save the file on your own machine or on a machine which the destination server can access.
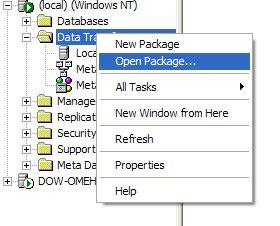
Then to open the package on the other server do this:
Right click on the Data Transformation Services folder, select open packages and navigate to the location where the Structured Storage File has been saved (see picture below)
And that is it.
First way: Just save it on the other server
From the location dropdown select SQL server, enter the IP or sever name and supply the credentials and you are done. click on the image below this text to see a larger image
Second way: Save the package as a Structured Storage File
Most of the times you won't be able to save the file directly on the destination server. The server might be in a DMZ and behind a couple of firewalls. In that case you can save the package as a Structured Storage File. From the dropdown select Structured Storage File (see picture below) Give the file a name and save it in a folder. You probably won't be able to save the file on the destination server, save the file on your own machine or on a machine which the destination server can access.

Then to open the package on the other server do this:
Right click on the Data Transformation Services folder, select open packages and navigate to the location where the Structured Storage File has been saved (see picture below)
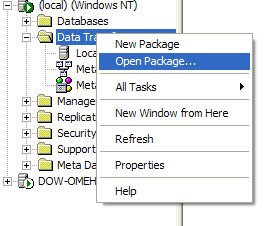
And that is it.
Saturday, October 14, 2006
Datamining Speech In SQL Server 2005
I decided to capture everything that my 2 and a half year old son says, store it in a SQL server 2005 database and run some statistics
This is the outcome in order of most words used
NO
Watch
Movie
Barney
Blues Clues
Dada
Mama
Hungry
Cookies
Chocolate
Icecream
As you can see dada is higher than mama (by a count of one)
So this is interesting, as a child approaches the terrible two’s the most used word is no. The second interesting thing is that watch was used 6300 times and Barney, Movie and Blues Clues 2100 times each. It looks like my son likes his entertainment evenly split. And of course junk food is also high on the list, broccoli is not even in the top 100
So how did I do this? Well I used this tool called Komodo Unnatural Speaking. This is a chip embedded in a sticker. The chip captures all speech and because it’s a RFID tag whenever my son passes a certain spot in the house the data is downloaded to my computer and the chip is cleared. A SSIS package uses Fuzzy Logic to process the data (a toddler’s speech is sometimes gibberish). We get rid of noise words and the results are stored in a table.
Pretty interesting don't you think? ;-)
This is the outcome in order of most words used
NO
Watch
Movie
Barney
Blues Clues
Dada
Mama
Hungry
Cookies
Chocolate
Icecream
As you can see dada is higher than mama (by a count of one)
So this is interesting, as a child approaches the terrible two’s the most used word is no. The second interesting thing is that watch was used 6300 times and Barney, Movie and Blues Clues 2100 times each. It looks like my son likes his entertainment evenly split. And of course junk food is also high on the list, broccoli is not even in the top 100
So how did I do this? Well I used this tool called Komodo Unnatural Speaking. This is a chip embedded in a sticker. The chip captures all speech and because it’s a RFID tag whenever my son passes a certain spot in the house the data is downloaded to my computer and the chip is cleared. A SSIS package uses Fuzzy Logic to process the data (a toddler’s speech is sometimes gibberish). We get rid of noise words and the results are stored in a table.
Pretty interesting don't you think? ;-)
Friday, October 13, 2006
SQL Teaser/Puzzle Inspired By Hugo Kornelis
Hugo Kornelis has posted an interesting article about using STUFF
The link to that article is here
He has a challenge in that article, the challenge is this:
Create this table
CREATE TABLE BadData (FullName varchar(20) NOT NULL);
INSERT INTO BadData (FullName)
SELECT 'Clinton, Bill' UNION ALL
SELECT 'Johnson, Lyndon, B.' UNION ALL
SELECT 'Bush, George, H.W.';
Split the names into 3 columns (not fields ;-) ), the shortest query wins
Your output should be this:
LastName FirstName MiddleInitial
Clinton Bill
Johnson Lyndon B.
Bush George H.W.
Hugo Kornelis posted a solution by using STUFF
SELECT FullName,LEFT(FullName, CHARINDEX(', ', FullName) - 1) AS LastName,
STUFF(LEFT(FullName, CHARINDEX(', ', FullName + ', ',CHARINDEX(', ', FullName) + 2) - 1), 1, CHARINDEX(', ', FullName) + 1, '') AS FirstName,
STUFF(FullName, 1,CHARINDEX(', ', FullName + ', ',
CHARINDEX(', ', FullName) + 2), '') AS MiddleInitial
FROM BadData
which according to editplus is 340 characters
I replied with this
SELECT FullName,PARSENAME(FullName2,NameLen+1) AS LastName,
PARSENAME(FullName2,NameLen) AS FirstName,
COALESCE(REPLACE(PARSENAME(FullName2,NameLen-1),'~','.'),'') AS MiddleInitial
FROM(
SELECT LEN(FullName) -LEN(REPLACE(FullName,',','')) AS NameLen,
REPLACE(REPLACE(FullName,'.','~'),', ','.') AS FullName2,FullName
FROM BadData) x
my solution is 338 characters, so 2 characters less ;-)
Of course I could have 'cheated' a little by doing this
SELECT FullName,PARSENAME(F,NameLen+1) AS LastName,
PARSENAME(F,NameLen) AS FirstName,
COALESCE(REPLACE(PARSENAME(F,NameLen-1),'~','.'),'') AS MiddleInitial
FROM(
SELECT LEN(FullName) -LEN(REPLACE(FullName,',','')) AS NameLen,
REPLACE(REPLACE(FullName,'.','~'),', ','.') AS F,FullName
FROM BadData) x
And this is 306 characters
So let's see, who can do it in less characters
The link to that article is here
He has a challenge in that article, the challenge is this:
Create this table
CREATE TABLE BadData (FullName varchar(20) NOT NULL);
INSERT INTO BadData (FullName)
SELECT 'Clinton, Bill' UNION ALL
SELECT 'Johnson, Lyndon, B.' UNION ALL
SELECT 'Bush, George, H.W.';
Split the names into 3 columns (not fields ;-) ), the shortest query wins
Your output should be this:
LastName FirstName MiddleInitial
Clinton Bill
Johnson Lyndon B.
Bush George H.W.
Hugo Kornelis posted a solution by using STUFF
SELECT FullName,LEFT(FullName, CHARINDEX(', ', FullName) - 1) AS LastName,
STUFF(LEFT(FullName, CHARINDEX(', ', FullName + ', ',CHARINDEX(', ', FullName) + 2) - 1), 1, CHARINDEX(', ', FullName) + 1, '') AS FirstName,
STUFF(FullName, 1,CHARINDEX(', ', FullName + ', ',
CHARINDEX(', ', FullName) + 2), '') AS MiddleInitial
FROM BadData
which according to editplus is 340 characters
I replied with this
SELECT FullName,PARSENAME(FullName2,NameLen+1) AS LastName,
PARSENAME(FullName2,NameLen) AS FirstName,
COALESCE(REPLACE(PARSENAME(FullName2,NameLen-1),'~','.'),'') AS MiddleInitial
FROM(
SELECT LEN(FullName) -LEN(REPLACE(FullName,',','')) AS NameLen,
REPLACE(REPLACE(FullName,'.','~'),', ','.') AS FullName2,FullName
FROM BadData) x
my solution is 338 characters, so 2 characters less ;-)
Of course I could have 'cheated' a little by doing this
SELECT FullName,PARSENAME(F,NameLen+1) AS LastName,
PARSENAME(F,NameLen) AS FirstName,
COALESCE(REPLACE(PARSENAME(F,NameLen-1),'~','.'),'') AS MiddleInitial
FROM(
SELECT LEN(FullName) -LEN(REPLACE(FullName,',','')) AS NameLen,
REPLACE(REPLACE(FullName,'.','~'),', ','.') AS F,FullName
FROM BadData) x
And this is 306 characters
So let's see, who can do it in less characters
Tuesday, October 10, 2006
An Interview With Ken Henderson About The Forthcoming Book SQL Server 2005 Practical Troubleshooting: The Database Engine
 I am a big fan of Ken Henderson’s books, I believe that every SQL Server developer should have a copy of his books. When I noticed on Amazon.com that the book SQL Server 2005 Practical Troubleshooting: The Database Engine which listed Ken Henderson as its editor would be coming out soon I got very excited. I decided to send Ken an email to see if he would be willing to answer some questions I had about the book. To my surprise Ken was more than willing to accommodate my request.
I am a big fan of Ken Henderson’s books, I believe that every SQL Server developer should have a copy of his books. When I noticed on Amazon.com that the book SQL Server 2005 Practical Troubleshooting: The Database Engine which listed Ken Henderson as its editor would be coming out soon I got very excited. I decided to send Ken an email to see if he would be willing to answer some questions I had about the book. To my surprise Ken was more than willing to accommodate my request.The question-and-answer session with Ken that follows was conducted via email.
Denis: What is the audience for this book, is it the enterprise user or can a small department benefit from the tips in this book?
Ken: Both types of users would benefit. Anyone who’s ever had a problem with SQL Server has probably noticed how few resources there are out there for troubleshooting SQL Server issues. There are plenty of resources that talk about how it works. There are many that discuss how to write code for it. But there are scant few that talk about what to do when something goes wrong. This book is intended for that audience. It is also intended for those who want to better understand how the product works and to be prepared in the event that something does go wrong with it. SQL Server doesn’t break often, but, when it does, this book will help you deal with it.
Denis: For a customer who has a performance problem that is not hardware related, what would you say are the most important chapters in this book (in order of importance)?
Ken: The Query Processor Issues chapter and the Procedure Cache Issues chapter are the two best for this type of problem.
Denis: Seven developers from the SQL Server development team and three support professionals from Microsoft Customer Support Services wrote this book. What took so long to write a book like this, and why wasn’t there a SQL Server 2000 version? Is it because SQL Server has truly grown to be a major player in the enterprise market and there is a definitive need for a book like this now?
Ken: The book took so long because all of the authors are first-time authors, and they are very busy people. There was no SQL Server 2000 version because I was too busy with my own projects to begin this project back then. SQL Server is indeed a major player in the enterprise, but I believe it has been since SQL Server 7.0. That particular aspect had nothing to do with the timing of this book.
Denis: I noticed you are listed as editor of this book. Have you written any chapters in this book?
Ken: No, I did not write any of the chapters of the book. I also tried to preserve each author’s writing style. Each chapter includes its own byline, and I have edited them as little as possible. Because some of the authors were more capable than others, I necessarily had to be involved to varying degrees with each chapter. Some chapters needed lots of editing; some very little. I think each individual perspective represented in the book is a valuable one, but I also think they speak in unison on the important points of practical troubleshooting with SQL Server.
Denis: What new technologies in SQL Server 2005 do you think are the most beneficial for performance?
Ken: There are really too many to list. A few that come to mind at the moment: instant file growth, improved wildcard support, more sophisticated cache management, improved scaling on big hardware, the XML data type and richer XML support in general, CLR integration, etc.
Denis: This book as I understand has a lot of internals information from the people who either wrote the product or have supported it that currently is not available anywhere else--is that right?
Ken: Yes, the majority of the authors were actually developers on the product. A few were support engineers who supported the product. All have had full access to the SQL Server source code for many years.
Denis: What will a person who reads this book gain in terms of understanding how to performance tune a server?
Ken: They will better understand both how the server works and also how to recognize and troubleshoot common performance problems.
Denis: Is the book geared towards a beginner/intermediate level user or do you have to be an advanced user to really utilize the information in this book?
Ken: There is something in this book for everyone. I’d like to think that beginners, intermediates, and advanced users alike would benefit from reading it.
Denis: What are the most important things a person can do to master SQL Server?
Ken: Naturally, the best thing a person could do would be to do what the authors of this book did: study the SQL Server source code. Studying the SQL Server source gives you insight into how the product works that is impossible to gain through any other means. But, given that that excludes pretty much everyone outside of Microsoft, here are some general thoughts:
#1, understand how Windows works at a very low level and how SQL Server utilizes the many facilities it offers
#2, understand how the product was designed and how it was intended to be used
#3, explore it not only as a user, but as a developer. Fire up a debugger and see how it works under the hood
#4, build real apps with it, using its various components as they were intended to be used
Denis: What are the most important things a person can do to master Transact-SQL?
Ken: My initial thought is that, again, studying the SQL Server source code is the shortest path to the deepest understanding of the language. That said, here are some general thoughts in no particular order:
#1, understand how SQL Server works. Understand the intricacies of performance tuning on SQL Server. Know how data is stored. Understand memory management and scheduling at a very low level. Understand logging and tempdb semantics. Remember that SQL Server is just an application. It’s not magical and can be misused and abused just like any other app
#2, learn the syntax and semantics of the language inside-out. Get a feel for its strengths and weaknesses, and code to those strengths. Always lean toward writing set-oriented code when you can
#3, study solutions to hard problems that are available in various forms, and apply the techniques you learn to solve your own problems
#4, learn other SQL dialects so that you can become familiar with their unique attributes and understand how T-SQL compares with them. Gain an understanding of where T-SQL fits in the general taxonomy of SQL dialects
#5, learn other languages besides SQL. If your favorite programming language is T-SQL, you probably don’t know many languages. Learn C#, VB, Perl, Ruby, C++, or any others you can work into your research so that you can better understand software engineering as a discipline and so that you can more clearly see T-SQL’s strengths and weaknesses when compared with those other languages. Try to see where you might apply techniques from those other languages to solve problems you encounter in T-SQL. Familiarize yourself with what a design pattern is, what an idiom is, what refactoring is, and apply these concepts in T-SQL just as you would in any other “real” language
#6, understand the various SQL Server components and other technologies so that you can accurately ascertain when it’s appropriate to use T-SQL. It’s not the solution for every problem. As the old saying goes, “When all you have is a hammer, everything starts to look like a nail.” By broadening your knowledge of the tools and problem solutions available to you, you’ll be more likely to choose the best one when deciding how to design a piece of software or solve a particular problem. T-SQL may turn out not to be the best way to go in a given situation
And I will end with 9 questions for Ken not related to this book
Denis: What SQL Server books are on your bookshelf?
Ken: I have Celko’s books, Darren Green’s book, and a few others. Unfortunately, I don’t have time to read as much as I’d like. I spend most of my time either writing code for the product or studying code written by others on the SQL Server development team. The majority of my research into how SQL Server works happens via studying its source code directly.
Denis: Why do you write technical books?
Ken: I write technical books because I enjoy passing on what I’ve learned as a developer. That’s different from enjoying teaching people. I do enjoy teaching people, but that’s not why I write books. Some of the things I’ve learned about SQL Server took me years to master. I enjoy passing that on to people so that they don’t have to travel the same arduous roads that I did. I enjoy helping people. That’s different from teaching for the sake of teaching. I could never train people for a living. I am a programmer by trade, and everything else is an offshoot of that.
If I didn’t think I had something unique to bring to the discussion, I don’t think I’d write books. I don’t ever want to do what has already been done. I want to bring a fresh perspective to technical books, and I want to explore things in ways most other authors wouldn’t. If my work was exactly like everyone else’s, there’d be no reason for it to exist, and I wouldn’t bother. Given that I’ve never written fulltime but have always held down a regular day job while writing my books, the work itself is simply too hard to do just to be a clone of someone else. When people pick up one of my books, I hope they know right away that it’s one of mine, that it speaks with a distinctive voice, and I hope they think they might learn something from it simply because they trust me as an author.
Denis: Why did you join Microsoft?
Ken: I joined Microsoft to get inside SQL Server. I felt that the only way to go beyond the books and whitepapers currently out there on SQL Server was to see the source code for myself, and the only way that was going to happen is if I joined the company. I wanted to approach the exploration of SQL Server from a career developer’s standpoint, something that I had not seen done before. Most SQL Server books were written by professional trainers and former DBAs. As a career developer, I thought I could bring a fresh perspective to the coverage of SQL Server, and I felt the only way to really do that was to “go live with the natives” for a few years.
Denis: Who are your favorite authors?
Ken: Mark Twain, Kurt Vonnegut, Bart D. Erhman, Robert Price, Dean Koontz, Stephen King, Joe Celko, Sam Harris, Richard Carrier, Don Box, David Solomon, Charles Petzold, Kent Beck, Martin Fowler, Bruce Eckel, and many others.
Denis: Who do you consider your rival authors?
Ken: I don’t really think of anyone else out there as a rival. When I write a book, I mainly measure my work against my concept of the perfect book. I write for me. There’s a great book out there titled On Writing Well where the author, William Zinsser, repeats the old truism that quality is its own reward. It really is. I love the fact that people enjoy my books, but, really, the day I finish the final draft of a book and can say that I’m really done with it (at least for the moment :-) ), I’ve accomplished my goal. If it never sold a copy, I’d still feel fulfilled. I do care how it sells against other books, but I don’t really focus on it and don’t get caught up in any type of rivalries with other authors or other books.
Because I always want to write a better book than I wrote last time, I necessarily compete with my previous work and I compete against what I think the ideal technical book is. I think there’s enough room out there for lots of technical authors (it’s not as though people only buy one technical book and no others), and I have special empathy for my comrades out there who have to slog along in the middle of the night to crank their books out.
Denis: Where did the “Guru’s Guide” concept come from?
Ken: Wayne Snyder, one of the MVPs reviewing the manuscript for the first Guru’s Guide (which was at that time unnamed), wrote in the margin, “Hey, Ken, this is really a guru’s guide to solutions to hard T-SQL problems!” at which point the marketing folk at Addison-Wesley saw this and seized upon it. We had kicked around several titles, but hadn’t settled on any of them. As soon as they saw this, they pushed me hard to use it, and I reluctantly agreed. I didn’t like it initially because I thought the title of a technical book should focus on either the subject material or its intended audience, not its author. There was an understanding that we’d revisit the title when we did the second book (I was originally under contract to do three SQL Server books for Addison-Wesley), but then sales of the first book exploded, and there was no way we could change it at that point.
Denis: What do you think of all the accolades the Guru’s Guide books have received?
Ken: I am appreciative of them, but continue to be surprised by the longevity of the books and the reception they’ve garnered. I thought I was writing a niche book when I wrote that first Guru’s Guide book. I just wanted to get down everything I knew about T-SQL before I forgot it ;-). I will continue to write the kinds of books I like to read as long as people will buy them, so I hope that people continue to enjoy my work.
Denis: Will you be updating your Guru’s Guide books for SQL Server 2005? If so, when will they be out?
Ken: Yes. The second editions of the Guru’s Guide books should be out in 2007.
Denis: Describe your most unpleasant experience as an author.
Ken: I had a particularly unpleasant experience during the work on my architecture book when I had to send one of the technical reviewers packing. He was someone who’d provided useful feedback on my work in the past and someone I’d handpicked to review the book for technical issues. I usually appreciate negative feedback during the technical review process and generally consider it the most useful type of feedback, but this reviewer focused more on arguing with me about what should and shouldn’t be in the book than reviewing what was there for technical accuracy. He had a problem with the fact that I spent the first 300 pages of the book (the book ended up being over 1000 pages long) covering fundamental concepts (e.g., Windows internals) that I thought people needed to understand in order to understand the rest of the book.
I had seen people within Microsoft struggle to understand SQL Server internals because they did not have a good grasp of how Windows worked or how XML worked or how COM worked, or whatever, and, assuming readers would likely face the same types of challenges, I set out to remedy that in my book. I also wanted to go deeper than any SQL Server book ever had, and that necessitated being able to assume a certain amount of fundamental knowledge going in. I wrote him back after his first objection to the section and told him that, while I respected his opinion, I had my reasons for including it, and I explained those reasons as best I could.
He suggested I just refer people to authors like Richter and Solomon and those guys, and I told him I’d considered that, but that ultimately I felt that would be cutting corners and would be a huge inconvenience since readers would have to purchase several other books just to understand mine. No single other book had all the technical fundamentals I felt were essential, nor did any of them cover the material the way that I wanted it covered--in a manner that was designed especially for DBAs and database people. At the same time, most readers wouldn’t be able to skip the fundamentals coverage in some form or fashion because they wouldn’t be able to understand my SQL Server internals coverage without it. While it was certainly a huge amount of work for me to include this section (it was much like writing a whole separate book), I felt it was the right thing to do.
He persisted with his objections and continued to voice them not only to me but also to the editing team at Addison-Wesley. I told him on several occasions that I respected his opinion, but that, as the author, the call was mine to make and that I’d made it. This seemed to irritate him, and he continued to consume a certain amount of my time with correspondence related to the subject. At one point, I counted 7 separate threads from him on that one subject in my Inbox, and the folks at Addison-Wesley had begun to complain about him. The fundamentals section, and his negative remarks regarding it, came to dominate all the feedback we got from him. While other reviewers were either indifferent to the coverage of Windows internals in a SQL Server book (it was certainly a novel approach) or embraced it outright, he became increasingly more negative as we went along. We got useful feedback on the entirety of the manuscript from all the other reviewers, but he seemed unable to move on from the fundamentals issue. Eventually, I had my fill of dealing with him and cut him loose from the project. I’m a fairly patient person, but I just didn’t have time to deal with him anymore.
Technical reviewers sometimes get on crusades and attempt to usurp the role of the author to some extent. Until this happened, I’d never personally experienced it, but I’d heard of it. At the end of the day, the decision as to what is and isn’t in a book is the author’s to make, and the role of the technical reviewer is to identify technical issues with whatever it is that will be in the book. Decisions about content belong to the author, and, to a lesser extent, the publisher and the publisher’s editing team. I guess the lesson I learned here was to be more careful with whom I select for involvement with my projects. I always want honest feedback, and, fortunately, I know a lot of people who will happily point out every technical issue they find with my work without trying to become a de facto coauthor.
About the book:
Paperback: 456 pages
Publisher: Addison-Wesley; 1ST edition
Language: English
ISBN: 0321447743
Contents
Preface
Chapter 1 Waiting and Blocking Issues
Chapter 2 Data Corruption and Recovery Issues
Chapter 3 Memory Issues
Chapter 4 Procedure Cache Issues
Chapter 5 Query Processor Issues
Chapter 6 Server Crashes and Other Critical Failures
Chapter 7 Service Broker Issues
Chapter 8 SQLOS and Scheduling Issues
Chapter 9 Tempdb Issues
Chapter 10 Clustering Issues
Index
Thanks to Ken for answering all these questions and if there is one reason this year to buy your own holiday gift then SQL Server 2005 Practical Troubleshooting: The Database Engine is it
Amazon Links:






Monday, October 09, 2006
sys.identity_columns
This is the third(see edit below) catalog view that I will cover, I have already covered sys.dm_exec_sessions and sys.dm_db_index_usage_stats For a list of all the catalog views click here
EDIT: Obviously I need to get more sleep because sys.identity_columns is not one of the Dynamic Management Views
Today we will talk about the sys.identity_columns Object Catalog View
The view sys.identity_columns contains a row for each column that is an identity column
If you look at this view in Books On Line you will notice that there are only 4 columns described
seed_value
increment_value
last_value
is_not_for_replication
However when you run SELECT * FROM sys.identity_columns you get back 26 columns. My first impression was that the documentation was incomplete, however when you look closer you will see that the first thing mentioned is
[columns inherited from sys.columns] For a list of columns that this view inherits, see sys.columns (Transact-SQL).
So this view return 4 columns in addition to what the sys.columns view returns
Make sure that you are using SQL Server 2005 and are in the AdventureWorks database
Okay so let's start, the way I write about these views is that I don't want to just copy what is in BOL. I try to have a couple of queries that will show you how to accomplish some things by using these views
Let's select all columns that have the identity property set by using the sys.columns view
SELECT *
FROM sys.columns
WHERE is_identity =1
Now run the following query
SELECT *
FROM sys.identity_columns
As you can see you get back the same number of rows only you get 4 additional columns back which have some information that only deal with identity columns
EDIT: Someone left me a comment (thank you) and I decided to update the post, the following query
SELECT * FROM sys.columns
WHERE is_identity =1
will return a column names is_computed, but the following query below will not
SELECT *
FROM sys.identity_columns
Which makes sense since an identity column can not be computed
END EDIT
Let's try some other things, let's select only the columns that have a tinyint as an identity column, this is easy to do we just join with the sys.types view
SELECT i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE t.name ='tinyint'
Or let's see how many different integer data types have the identity property set
SELECT t.name,COUNT(*) as GroupedCount
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
GROUP BY t.name
And the results are below
name GroupedCount
----------------------
bigint 3
int 43
smallint 3
tinyint 2
So that is all fine but how do we know what table this column belongs to? That's pretty easy to do we can just use the OBJECT_NAME function
--tinyint only
SELECT OBJECT_NAME(object_id) AS TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE t.name ='tinyint'
--smallint only
SELECT OBJECT_NAME(object_id) AS TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE t.name ='smallint'
There is a small problem with using OBJECT_NAME(object_id) to get the table name
We should be using this instead
SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) as FullTableName
Why am I doing this? This is because SQL server 2005 introduced schemas
so basically if we do this
SELECT * FROM HumanResources.Department
we have no problem, but if we run the following query
SELECT * FROM Department
we get this friendly message
Server: Msg 208, Level 16, State 1, Line 1
Invalid object name 'Department'.
Now let's create a Department table
CREATE TABLE Department (ID INT IDENTITY NOT NULL)
When we run this query
SELECT SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,
CASE t.name WHEN 'tinyint' THEN 255 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'smallint' THEN 32767 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'int' THEN 2147483647 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'bigint' THEN 9223372036854775807 -COALESCE(CONVERT(INT,last_value),0)
END AS ValuesLeft ,
OBJECT_NAME(object_id) as TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_Value > 0
AND OBJECT_NAME(object_id) like 'DE%'
ORDER BY TableName
We will see two rows
dbo.Department 2147483647 Department int
HumanResources.Department 32751 Department smallint
One table is dbo.Department and the other table is HumanResources.Department
Now when we run the same queries again there is no problem
SELECT * FROM Department
SELECT * FROM HumanResources.Department
You can read up more on schemas in BOL, let's get back to sys.identity_columns
let's do something interesting now, let's find out how many more identity values we have left until we run out
SELECT SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,
CASE t.name WHEN 'tinyint' THEN 255 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'smallint' THEN 32767 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'int' THEN 2147483647 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'bigint' THEN 9223372036854775807 -COALESCE(CONVERT(INT,last_value),0) END AS ValuesLeft ,
OBJECT_NAME(object_id) as TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_Value > 0
ORDER BY FullTableName
You can also calculate the percentage used
SELECT SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,
CASE t.name WHEN 'tinyint' THEN 100 -(255 -COALESCE(CONVERT(INT,last_value),0)) /255.0 * 100
WHEN 'smallint' THEN 100 -( 32767 -COALESCE(CONVERT(INT,last_value),0)) /32767.0 * 100
WHEN 'int' THEN 100 -(2147483647 -COALESCE(CONVERT(INT,last_value),0)) /2147483647.0 * 100
WHEN 'bigint' THEN 100 -(9223372036854775807 -COALESCE(CONVERT(INT,last_value),0)) /9223372036854775807.0 * 100
END AS PercentageUsed ,
OBJECT_NAME(object_id) as TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_Value > 0
ORDER BY PercentageUsed DESC
Now let's find all the columns where the seed value is not 1
SELECT seed_value,SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_value > 1
ORDER BY FullTableName
Now let's find all the columns where the increment value is not 1
SELECT increment_value,SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE increment_value <> 1
ORDER BY FullTableName
No rows are returned, now let's put that to the test by creating a table and have the value increment by 5
CREATE TABLE dbo.Department2 (ID INT IDENTITY (1,5) NOT NULL)
Now run the query again
SELECT increment_value,SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE increment_value <> 1
ORDER BY FullTableName
And that covers some uses of the sys.identity_columns view, the only thing left is the description of the view itself
Column name
Data type Description
object_id
int ID of the object to which this column belongs.
name
sysname Name of the column. Is unique within the object.
column_id
int ID of the column. Is unique within the object.
Column IDs might not be sequential.
system_type_id
tinyint ID of the system type of the column.
user_type_id
int ID of the type of the column as defined by the user.
To return the name of the type, join to the sys.types catalog view on this column.
max_length
smallint Maximum length (in bytes) of the column.
-1 = Column data type is varchar(max), nvarchar(max), varbinary(max), or xml.
For text columns, the max_length value will be 16 or the value set by sp_tableoption 'text in row'.
precision
tinyint Precision of the column if numeric-based; otherwise, 0.
scale
tinyint Scale of column if numeric-based; otherwise, 0.
collation_name
sysname Name of the collation of the column if character-based; otherwise, NULL.
is_nullable
bit 1 = Column is nullable.
is_ansi_padded
bit 1 = Column uses ANSI_PADDING ON behavior if character, binary, or variant.
0 = Column is not character, binary, or variant.
is_rowguidcol
bit 1 = Column is a declared ROWGUIDCOL.
is_identity
bit 1 = Column has identity values
is_filestream
bit Reserved for future use.
is_replicated
bit 1 = Column is replicated.
is_non_sql_subscribed
bit 1 = Column has a non-SQL Server subscriber.
is_merge_published
bit 1 = Column is merge-published.
is_dts_replicated
bit 1 = Column is replicated by using SQL Server 2005 Integration Services (SSIS).
is_xml_document
bit 1 = Content is a complete XML document.
0 = Content is a document fragment or the column data type is not xml.
xml_collection_id
int Nonzero if the data type of the column is xml and the XML is typed. The value will be the ID of the collection containing the validating XML schema namespace of the column.
0 = No XML schema collection.
default_object_id
int ID of the default object, regardless of whether it is a stand-alone object sys.sp_bindefault, or an inline, column-level DEFAULT constraint. The parent_object_id column of an inline column-level default object is a reference back to the table itself.
0 = No default.
rule_object_id
int ID of the stand-alone rule bound to the column by using sys.sp_bindrule.
0 = No stand-alone rule. For column-level CHECK constraints, see sys.check_constraints (Transact-SQL).
seed_value
sql_variant Seed value for this identity column. The data type of the seed value is the same as the data type of the column itself.
increment_value
sql_variant Increment value for this identity column. The data type of the seed value is the same as the data type of the column itself.
last_value
sql_variant Last value generated for this identity column. The data type of the seed value is the same as the data type of the column itself.
is_not_for_replication
bit Identity column is declared NOT FOR REPLICATION.
EDIT: Obviously I need to get more sleep because sys.identity_columns is not one of the Dynamic Management Views
Today we will talk about the sys.identity_columns Object Catalog View
The view sys.identity_columns contains a row for each column that is an identity column
If you look at this view in Books On Line you will notice that there are only 4 columns described
seed_value
increment_value
last_value
is_not_for_replication
However when you run SELECT * FROM sys.identity_columns you get back 26 columns. My first impression was that the documentation was incomplete, however when you look closer you will see that the first thing mentioned is
[columns inherited from sys.columns] For a list of columns that this view inherits, see sys.columns (Transact-SQL).
So this view return 4 columns in addition to what the sys.columns view returns
Make sure that you are using SQL Server 2005 and are in the AdventureWorks database
Okay so let's start, the way I write about these views is that I don't want to just copy what is in BOL. I try to have a couple of queries that will show you how to accomplish some things by using these views
Let's select all columns that have the identity property set by using the sys.columns view
SELECT *
FROM sys.columns
WHERE is_identity =1
Now run the following query
SELECT *
FROM sys.identity_columns
As you can see you get back the same number of rows only you get 4 additional columns back which have some information that only deal with identity columns
EDIT: Someone left me a comment (thank you) and I decided to update the post, the following query
SELECT * FROM sys.columns
WHERE is_identity =1
will return a column names is_computed, but the following query below will not
SELECT *
FROM sys.identity_columns
Which makes sense since an identity column can not be computed
END EDIT
Let's try some other things, let's select only the columns that have a tinyint as an identity column, this is easy to do we just join with the sys.types view
SELECT i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE t.name ='tinyint'
Or let's see how many different integer data types have the identity property set
SELECT t.name,COUNT(*) as GroupedCount
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
GROUP BY t.name
And the results are below
name GroupedCount
----------------------
bigint 3
int 43
smallint 3
tinyint 2
So that is all fine but how do we know what table this column belongs to? That's pretty easy to do we can just use the OBJECT_NAME function
--tinyint only
SELECT OBJECT_NAME(object_id) AS TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE t.name ='tinyint'
--smallint only
SELECT OBJECT_NAME(object_id) AS TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE t.name ='smallint'
There is a small problem with using OBJECT_NAME(object_id) to get the table name
We should be using this instead
SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) as FullTableName
Why am I doing this? This is because SQL server 2005 introduced schemas
so basically if we do this
SELECT * FROM HumanResources.Department
we have no problem, but if we run the following query
SELECT * FROM Department
we get this friendly message
Server: Msg 208, Level 16, State 1, Line 1
Invalid object name 'Department'.
Now let's create a Department table
CREATE TABLE Department (ID INT IDENTITY NOT NULL)
When we run this query
SELECT SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,
CASE t.name WHEN 'tinyint' THEN 255 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'smallint' THEN 32767 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'int' THEN 2147483647 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'bigint' THEN 9223372036854775807 -COALESCE(CONVERT(INT,last_value),0)
END AS ValuesLeft ,
OBJECT_NAME(object_id) as TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_Value > 0
AND OBJECT_NAME(object_id) like 'DE%'
ORDER BY TableName
We will see two rows
dbo.Department 2147483647 Department int
HumanResources.Department 32751 Department smallint
One table is dbo.Department and the other table is HumanResources.Department
Now when we run the same queries again there is no problem
SELECT * FROM Department
SELECT * FROM HumanResources.Department
You can read up more on schemas in BOL, let's get back to sys.identity_columns
let's do something interesting now, let's find out how many more identity values we have left until we run out
SELECT SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,
CASE t.name WHEN 'tinyint' THEN 255 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'smallint' THEN 32767 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'int' THEN 2147483647 -COALESCE(CONVERT(INT,last_value),0)
WHEN 'bigint' THEN 9223372036854775807 -COALESCE(CONVERT(INT,last_value),0) END AS ValuesLeft ,
OBJECT_NAME(object_id) as TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_Value > 0
ORDER BY FullTableName
You can also calculate the percentage used
SELECT SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,
CASE t.name WHEN 'tinyint' THEN 100 -(255 -COALESCE(CONVERT(INT,last_value),0)) /255.0 * 100
WHEN 'smallint' THEN 100 -( 32767 -COALESCE(CONVERT(INT,last_value),0)) /32767.0 * 100
WHEN 'int' THEN 100 -(2147483647 -COALESCE(CONVERT(INT,last_value),0)) /2147483647.0 * 100
WHEN 'bigint' THEN 100 -(9223372036854775807 -COALESCE(CONVERT(INT,last_value),0)) /9223372036854775807.0 * 100
END AS PercentageUsed ,
OBJECT_NAME(object_id) as TableName,t.name,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_Value > 0
ORDER BY PercentageUsed DESC
Now let's find all the columns where the seed value is not 1
SELECT seed_value,SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE seed_value > 1
ORDER BY FullTableName
Now let's find all the columns where the increment value is not 1
SELECT increment_value,SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE increment_value <> 1
ORDER BY FullTableName
No rows are returned, now let's put that to the test by creating a table and have the value increment by 5
CREATE TABLE dbo.Department2 (ID INT IDENTITY (1,5) NOT NULL)
Now run the query again
SELECT increment_value,SCHEMA_NAME(CAST(OBJECTPROPERTYEX(OBJECT_ID, 'SchemaId') AS INT))
+ '.' + OBJECT_NAME(OBJECT_ID) AS FullTableName,i.*
FROM sys.identity_columns i JOIN sys.types t ON i.user_type_id = t.user_type_id
WHERE increment_value <> 1
ORDER BY FullTableName
And that covers some uses of the sys.identity_columns view, the only thing left is the description of the view itself
Column name
Data type Description
object_id
int ID of the object to which this column belongs.
name
sysname Name of the column. Is unique within the object.
column_id
int ID of the column. Is unique within the object.
Column IDs might not be sequential.
system_type_id
tinyint ID of the system type of the column.
user_type_id
int ID of the type of the column as defined by the user.
To return the name of the type, join to the sys.types catalog view on this column.
max_length
smallint Maximum length (in bytes) of the column.
-1 = Column data type is varchar(max), nvarchar(max), varbinary(max), or xml.
For text columns, the max_length value will be 16 or the value set by sp_tableoption 'text in row'.
precision
tinyint Precision of the column if numeric-based; otherwise, 0.
scale
tinyint Scale of column if numeric-based; otherwise, 0.
collation_name
sysname Name of the collation of the column if character-based; otherwise, NULL.
is_nullable
bit 1 = Column is nullable.
is_ansi_padded
bit 1 = Column uses ANSI_PADDING ON behavior if character, binary, or variant.
0 = Column is not character, binary, or variant.
is_rowguidcol
bit 1 = Column is a declared ROWGUIDCOL.
is_identity
bit 1 = Column has identity values
is_filestream
bit Reserved for future use.
is_replicated
bit 1 = Column is replicated.
is_non_sql_subscribed
bit 1 = Column has a non-SQL Server subscriber.
is_merge_published
bit 1 = Column is merge-published.
is_dts_replicated
bit 1 = Column is replicated by using SQL Server 2005 Integration Services (SSIS).
is_xml_document
bit 1 = Content is a complete XML document.
0 = Content is a document fragment or the column data type is not xml.
xml_collection_id
int Nonzero if the data type of the column is xml and the XML is typed. The value will be the ID of the collection containing the validating XML schema namespace of the column.
0 = No XML schema collection.
default_object_id
int ID of the default object, regardless of whether it is a stand-alone object sys.sp_bindefault, or an inline, column-level DEFAULT constraint. The parent_object_id column of an inline column-level default object is a reference back to the table itself.
0 = No default.
rule_object_id
int ID of the stand-alone rule bound to the column by using sys.sp_bindrule.
0 = No stand-alone rule. For column-level CHECK constraints, see sys.check_constraints (Transact-SQL).
seed_value
sql_variant Seed value for this identity column. The data type of the seed value is the same as the data type of the column itself.
increment_value
sql_variant Increment value for this identity column. The data type of the seed value is the same as the data type of the column itself.
last_value
sql_variant Last value generated for this identity column. The data type of the seed value is the same as the data type of the column itself.
is_not_for_replication
bit Identity column is declared NOT FOR REPLICATION.
Non Technical: What Sleepless Nights?
 My wife took this picture and I just had to share it. I try to keep the non technical stuff for the weekends only but this was just too cute. When you look at a picture like this as a father you forget immediately that you have missed any sleep or that you son who is 2 and a half started his terrible two’s the moment he laid eyes on his brother and sister. However I will tell you that I have something very exiting related to SQL Server coming up this week so stay tuned……
My wife took this picture and I just had to share it. I try to keep the non technical stuff for the weekends only but this was just too cute. When you look at a picture like this as a father you forget immediately that you have missed any sleep or that you son who is 2 and a half started his terrible two’s the moment he laid eyes on his brother and sister. However I will tell you that I have something very exiting related to SQL Server coming up this week so stay tuned……
Saturday, October 07, 2006
SQL Server Utility SQLIOSim Is Available For Download
There are many components involved with reading and writing data to files. Starting from an application (SQL Server or SQLIOSim) the IO request is handed over to the Operating system via an API call. Once in the hands of the OS the request will travel through levels of filter drivers installed by things like antivirus software, backup utilities and finally find its way to a driver that will hand the actual data over to a disk controller, and eventually find its way to a disk or array of disks. There may be caching on the disks, and in the case of high end arrays there may also be logic to determine whether or not to service the request immediately or defer. If even one of these pieces get it wrong the results for your data would be disastrous.
Wouldn’t you rather know there is a problem before you entrust your data to such a complex process?
SQLIOSim is designed to generate exactly the same type and patterns of IO requests at a disk subsystem as SQL Server would, and verify the written data exactly as SQL Server would.
More details and download links are available here
Wouldn’t you rather know there is a problem before you entrust your data to such a complex process?
SQLIOSim is designed to generate exactly the same type and patterns of IO requests at a disk subsystem as SQL Server would, and verify the written data exactly as SQL Server would.
More details and download links are available here
Yahoo Launches .NET Developer Center, Windows Vista RC2 Available For Download
Yahoo Launches .NET Developer Center
Yahoo! Developer Network has launched .NET Developer Center.This site is your source for information about using the .NET Framework with Yahoo! Web Services and APIs. Here you'll find:
HOWTO Articles to help you understand our technologies and how you can use them better with .NET.
Download the sample browser, utility libraries and source code.
Other Resources on the web where you can find source code and helpful tools.
Community Resources where you can join our mailing list and discuss the Yahoo! APIs with us and with other .NET developers.
Windows Vista RC2 Available For Download
From the site: "Today, Microsoft is excited to announce the availability of Windows Vista RC2 to Technical Beta Testers, TAP Testers, and MSDN/TechNet subscribers. This new build of Windows Vista offers users a higher level of performance and stability – improving what was established in Windows Vista RC1. We were able to also fix many of your bugs reported from RC1 and implement them for RC2. Thank you to our beta testers for the bugs and feedback you submitted for RC1. The improvement shows as we raised our quality bar even higher!
"
Download it here
Yahoo! Developer Network has launched .NET Developer Center.This site is your source for information about using the .NET Framework with Yahoo! Web Services and APIs. Here you'll find:
HOWTO Articles to help you understand our technologies and how you can use them better with .NET.
Download the sample browser, utility libraries and source code.
Other Resources on the web where you can find source code and helpful tools.
Community Resources where you can join our mailing list and discuss the Yahoo! APIs with us and with other .NET developers.
Windows Vista RC2 Available For Download
From the site: "Today, Microsoft is excited to announce the availability of Windows Vista RC2 to Technical Beta Testers, TAP Testers, and MSDN/TechNet subscribers. This new build of Windows Vista offers users a higher level of performance and stability – improving what was established in Windows Vista RC1. We were able to also fix many of your bugs reported from RC1 and implement them for RC2. Thank you to our beta testers for the bugs and feedback you submitted for RC1. The improvement shows as we raised our quality bar even higher!
"
Download it here
Friday, October 06, 2006
SQL Server Blog Of The Week: Snaps & Snippets By Mi Lambda (Matija Lah)
So here we are it's Friday and you know what that means; it's time for our blog of the week. The blog of the week is snaps & snippets by Mi Lambda (Matija Lah). Matija Lah lives in Slovenia, I have visited Slovenia many times; I have been to Ljubljana, Maribor, Koper and Bled. The first I heard about this blog was in the microsoft public sql server programming forum, if you visit the forum look out for the author ML
What do I like about this blog
There are some cool tricks and tips in this blog and the posting go into a lot of detail. it's like reading a book
What are some at the posts I like the most
Column Dependencies and Consequences
Unidirectional synchronisation
Full synchronisation
Date[Time] constructor SQL-style
Where can I see/read/hear more about the author?
check the microsoft.public.sqlserver.programming forum
So there you have it; the SQL Server blog of the week
What do I like about this blog
There are some cool tricks and tips in this blog and the posting go into a lot of detail. it's like reading a book
What are some at the posts I like the most
Column Dependencies and Consequences
Unidirectional synchronisation
Full synchronisation
Date[Time] constructor SQL-style
Where can I see/read/hear more about the author?
check the microsoft.public.sqlserver.programming forum
So there you have it; the SQL Server blog of the week
Thursday, October 05, 2006
SQL Challenge: Random Grouping Of Data
After Omnibuzz's challenge this morning I decided to come up with a challenge of my own
Let's say you have a table with data (what else would be in the table bananas? )The data looks like this
sony 4
sony 6
toshiba 1
toshiba 3
mitsubishi 2
mitsubishi 5
You want to return the results grouped together by company name but in random order
So for example the first resultset is
sony 4
sony 6
toshiba 1
toshiba 3
mitsubishi 2
mitsubishi 5
you highlight the query hit F5 and the next result is
toshiba 1
toshiba 3
sony 4
sony 6
mitsubishi 2
mitsubishi 5
See where I am going? The resultset is random but the company names are grouped together
Here is the deal no CTE or windowing functions (RANK, DENSE_RANK, ROWNUMBER or NTILE) you know what forget about SQL Server 2005, this has to be able to run on SQL Server 2000
Also no temp tables or table variables (added after first response ;-) )
I have 2 solutions to this, I will post the solutions some time tomorrow
Below is DDL + Insert script
Enjoy
CREATE TABLE #Testcompanies (
Name VARCHAR(50),
ID INT)
INSERT INTO #Testcompanies
SELECT 'toshiba' ,1
UNION ALL
SELECT 'mitsubishi', 2
UNION ALL
SELECT 'toshiba', 3
UNION ALL
SELECT 'sony', 4
UNION ALL
SELECT 'mitsubishi', 5
UNION ALL
SELECT 'sony', 6
Here are the 2 solutions I had in mind
--Query using a sub query and NEWID()
SELECT T.*
FROM #Testcompanies T
JOIN (SELECT DISTINCT TOP 100 PERCENT Name,
NEWID() AS GroupedOrder
FROM #Testcompanies
GROUP BY Name
ORDER BY NEWID()) Z
ON T.Name = Z.Name
ORDER BY Z.GroupedOrder
--Query using RAND()
DECLARE @R FLOAT
SET @R = RAND()
SELECT TOP 100 PERCENT *
FROM #TESTCOMPANIES
ORDER BY RAND(@R * CHECKSUM(NAME))
Does anyone else have a different solution than these two or the two in the comments?
Let's say you have a table with data (what else would be in the table bananas? )The data looks like this
sony 4
sony 6
toshiba 1
toshiba 3
mitsubishi 2
mitsubishi 5
You want to return the results grouped together by company name but in random order
So for example the first resultset is
sony 4
sony 6
toshiba 1
toshiba 3
mitsubishi 2
mitsubishi 5
you highlight the query hit F5 and the next result is
toshiba 1
toshiba 3
sony 4
sony 6
mitsubishi 2
mitsubishi 5
See where I am going? The resultset is random but the company names are grouped together
Here is the deal no CTE or windowing functions (RANK, DENSE_RANK, ROWNUMBER or NTILE) you know what forget about SQL Server 2005, this has to be able to run on SQL Server 2000
Also no temp tables or table variables (added after first response ;-) )
I have 2 solutions to this, I will post the solutions some time tomorrow
Below is DDL + Insert script
Enjoy
CREATE TABLE #Testcompanies (
Name VARCHAR(50),
ID INT)
INSERT INTO #Testcompanies
SELECT 'toshiba' ,1
UNION ALL
SELECT 'mitsubishi', 2
UNION ALL
SELECT 'toshiba', 3
UNION ALL
SELECT 'sony', 4
UNION ALL
SELECT 'mitsubishi', 5
UNION ALL
SELECT 'sony', 6
Here are the 2 solutions I had in mind
--Query using a sub query and NEWID()
SELECT T.*
FROM #Testcompanies T
JOIN (SELECT DISTINCT TOP 100 PERCENT Name,
NEWID() AS GroupedOrder
FROM #Testcompanies
GROUP BY Name
ORDER BY NEWID()) Z
ON T.Name = Z.Name
ORDER BY Z.GroupedOrder
--Query using RAND()
DECLARE @R FLOAT
SET @R = RAND()
SELECT TOP 100 PERCENT *
FROM #TESTCOMPANIES
ORDER BY RAND(@R * CHECKSUM(NAME))
Does anyone else have a different solution than these two or the two in the comments?
Answer To A SQL Challenge By Omnibuzz (SQL Garbage Collector)
Omnibuzz has posted the following challenge: A scenario to ponder #1
This challenge is about returning a random number of customers and returnig them in random order, here is what he said:
Say you have a table:
Customers (CustomerID int primary key, CustomerName varchar(50))
A pretty simple table structure. And it has 1000 rows.
Now, I am conducting a contest for the customers where I will randomly pick up 5 to 20 customers every week and give away prizes.
How will I go about doing it?
I need to create a stored procedure/query/function that will accept no parameters but will return random list of customers and random number of customers (between 5 and 20)
And here is my solution
CREATE PROCEDURE ReturnRandomCustomers
AS
SET NOCOUNT ON
DECLARE @value INT
SELECT @value = CAST(5 + (RAND() * (20 - 5 + 1)) AS INT)
SELECT TOP @value *
FROM Customers
ORDER BY NEWID()
SET NOCOUNT OFF
GO
Since we are using SQL Server 2005 we can use TOP with a variable, and to set that variable we us the RAND function
The SQL Server 2000 version would look like this
CREATE PROCEDURE ReturnRandomCustomers
AS
SET NOCOUNT ON
DECLARE @value INT
SELECT @value = CAST(5 + (RAND() * (20 - 5 + 1)) AS INT)
SET ROWCOUNT @value
SELECT *
FROM Customers
ORDER BY NEWID()
SET ROWCOUNT 0
SET NOCOUNT OFF
GO
This challenge is about returning a random number of customers and returnig them in random order, here is what he said:
Say you have a table:
Customers (CustomerID int primary key, CustomerName varchar(50))
A pretty simple table structure. And it has 1000 rows.
Now, I am conducting a contest for the customers where I will randomly pick up 5 to 20 customers every week and give away prizes.
How will I go about doing it?
I need to create a stored procedure/query/function that will accept no parameters but will return random list of customers and random number of customers (between 5 and 20)
And here is my solution
CREATE PROCEDURE ReturnRandomCustomers
AS
SET NOCOUNT ON
DECLARE @value INT
SELECT @value = CAST(5 + (RAND() * (20 - 5 + 1)) AS INT)
SELECT TOP @value *
FROM Customers
ORDER BY NEWID()
SET NOCOUNT OFF
GO
Since we are using SQL Server 2005 we can use TOP with a variable, and to set that variable we us the RAND function
The SQL Server 2000 version would look like this
CREATE PROCEDURE ReturnRandomCustomers
AS
SET NOCOUNT ON
DECLARE @value INT
SELECT @value = CAST(5 + (RAND() * (20 - 5 + 1)) AS INT)
SET ROWCOUNT @value
SELECT *
FROM Customers
ORDER BY NEWID()
SET ROWCOUNT 0
SET NOCOUNT OFF
GO
Wednesday, October 04, 2006
Red Gate's SQL Refactor Public CTP Released
That great company Red Gate has released a public CTP of their latest tool SQL Refactor. Thanks to Louis Davidson for sharing this info, you can get all the details including a download link on his blog right here: http://drsql.spaces.live.com/blog/cns!80677FB08B3162E4!1422.entry
Download it, play with it and let me know what you think
Download it, play with it and let me know what you think
Tuesday, October 03, 2006
Three Team Edition for Database Professionals Screencasts On Channel 9
Channel 9 has three screencast about Team Edition for Database Professionals
Team Edition for DB Pros 5 min Demo
"I'd like to introduce you to the latest edition of Visual Studio Team System - Team Edition for Database Professionals.
Check out this quick 5 minute demo to get a whirlwind tour of exactly what Team Data can do for you."
Creating a database project with Team Edition for Database Professionals
"I'd like to introduce you to how to create your database project using the latest edition of Visual Studio Team System - Team Edition for Database Professionals.
Check out this quick 10 minute demo to get a whirlwind tour of project creation within VSTE for DB Pro."
Configuring Design DB for Team Edition for Database Professionals
"This video will describe how to install and configure SQL Server 2005 to support Visual Studio Team Edition for Database Professionals database projects.
Richard Waymire is the Program Management Architect for Visual Studio Team System for Database Professionals. He’s been with Microsoft for more than 8 years, having been in the SQL Server team for most of that time. He’s the author of several books on SQL Server, a contributing editor to SQL Server Magazine, and a frequent speaker at SQL Server events."
Enjoy them.
Team Edition for DB Pros 5 min Demo
"I'd like to introduce you to the latest edition of Visual Studio Team System - Team Edition for Database Professionals.
Check out this quick 5 minute demo to get a whirlwind tour of exactly what Team Data can do for you."
Creating a database project with Team Edition for Database Professionals
"I'd like to introduce you to how to create your database project using the latest edition of Visual Studio Team System - Team Edition for Database Professionals.
Check out this quick 10 minute demo to get a whirlwind tour of project creation within VSTE for DB Pro."
Configuring Design DB for Team Edition for Database Professionals
"This video will describe how to install and configure SQL Server 2005 to support Visual Studio Team Edition for Database Professionals database projects.
Richard Waymire is the Program Management Architect for Visual Studio Team System for Database Professionals. He’s been with Microsoft for more than 8 years, having been in the SQL Server team for most of that time. He’s the author of several books on SQL Server, a contributing editor to SQL Server Magazine, and a frequent speaker at SQL Server events."
Enjoy them.
Monday, October 02, 2006
SQL Server Teaser
Here is a quick SQL Server teaser
Create the following table
CREATE TABLE [barney ]
(
barneyId INT
)
Then look at the following 4 statements which one will fail?
Do not run the statements try to guess, Is it A, B, C or D (or more than one?)
--A
INSERT [barney ] VALUES (1)
--B
INSERT barney VALUES (1)
--C
INSERT "barney" VALUES (1)
--D
INSERT [barney] VALUES (1)
BTW the idea for this post came after reading "Another reason to hate quoted identifiers..." on Louis Davidson's blog
Create the following table
CREATE TABLE [barney ]
(
barneyId INT
)
Then look at the following 4 statements which one will fail?
Do not run the statements try to guess, Is it A, B, C or D (or more than one?)
--A
INSERT [barney ] VALUES (1)
--B
INSERT barney VALUES (1)
--C
INSERT "barney" VALUES (1)
--D
INSERT [barney] VALUES (1)
BTW the idea for this post came after reading "Another reason to hate quoted identifiers..." on Louis Davidson's blog
Top 5 Posts For September 2006
Below are the top 5 posts according to Google Analytics for the month of September 2006 in order by pageviews descending
Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
COALESCE And ISNULL Differences
Top 10 Articles of all time
OPENROWSET And Excel Problems
Store The Output Of A Stored Procedure In A Table Without Creating A Table
Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
COALESCE And ISNULL Differences
Top 10 Articles of all time
OPENROWSET And Excel Problems
Store The Output Of A Stored Procedure In A Table Without Creating A Table
Top SQL Server Google Searches For September 2006
These are the top SQL Searches on this site for the month of September I have left out searches that have nothing to do with SQL Server or programming (for example atlantic city escorts)
calculating application availability
pl/sql code to calculate application availability
vb .net Datagrid column naming
does not have the identity property
application availability report and pl/sql
autoincrement
datetime string
sqldatareader stored proc clr
OUTER JOIN
OUTER JOIN SQL 2000 example
I always find it interesting to see what people are searching for and it also gives me ideas for things to write about
calculating application availability
pl/sql code to calculate application availability
vb .net Datagrid column naming
does not have the identity property
application availability report and pl/sql
autoincrement
datetime string
sqldatareader stored proc clr
OUTER JOIN
OUTER JOIN SQL 2000 example
I always find it interesting to see what people are searching for and it also gives me ideas for things to write about
Sunday, October 01, 2006
iWoz: From Computer Geek to Cult Icon: How I Invented the Personal Computer, Co-Founded Apple, and Had Fun Doing It
 How I wish I had more time and needed less sleep (less than the 4-5 hours I am getting now) I am very excited about this book and will for sure put it on my Christmas list
How I wish I had more time and needed less sleep (less than the 4-5 hours I am getting now) I am very excited about this book and will for sure put it on my Christmas listBook Description
The mastermind behind Apple sheds his low profile and steps forward to tell his story for the first time.
Before cell phones that fit in the palm of your hand and slim laptops that fit snugly into briefcases, computers were like strange, alien vending machines. They had cryptic switches, punch cards and pages of encoded output. But in 1975, a young engineering wizard named Steve Wozniak had an idea: What if you combined computer circuitry with a regular typewriter keyboard and a video screen? The result was the first true personal computer, the Apple I, a widely affordable machine that anyone could understand and figure out how to use.
Wozniak's life—before and after Apple—is a "home-brew" mix of brilliant discovery and adventure, as an engineer, a concert promoter, a fifth-grade teacher, a philanthropist, and an irrepressible prankster. From the invention of the first personal computer to the rise of Apple as an industry giant, iWoz presents a no-holds-barred, rollicking, firsthand account of the humanist inventor who ignited the computer revolution. 16 pages of illustrations.
Amazon link is here for those interested
Return All 78498 Prime Numbers Between 1 and 1000000 Continues in the Land Down Under
So this Prime Number challenge won't die, the other day I wrote about it in THIS post. Rob Farley from Down Under let me a comment with two approaches he took, I decided to link to them from a seperate post. His first attempt is primes and his second attempt is More On Primes. His approach is interesting since he doesn't delete from the table but actually inserts into the table. Make sure you check it out
Friday, September 29, 2006
Trouble With ISDATE And Converting To SMALLDATETIME
If you want to use the ISDATE function to convert a value to a SMALLDATETIME you also have to take into consideration that SMALLDATETIME stores date and time data from January 1, 1900, through June 6, 2079 but DATETIME stores date and time data from January 1, 1753 through December 31, 9999
So even though the ISDATE function returns 1 for the date 1890-01-01 this can not be converted to SMALLDATETIME and you will receive an error message after you run the following statement
SELECT CONVERT(SMALLDATETIME,'18900101')
Server: Msg 296, Level 16, State 3, Line 1
The conversion of char data type to smalldatetime data type resulted in an out-of-range smalldatetime value.
Also be careful with rounding
Run these four statements
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:29')
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:29.998')
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:29.999')
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:30')
The first two are fine , the second two blow up because the value gets rounded up to the next day after it gets rounded up to the next minute (and hour)
I decided to roll out my own fnIsSmallDateTime() function because who wants to write the same CASE ISDATE when Value between this and that code all over the place?
Here is the code for the user defined function
CREATE FUNCTION fnIsSmallDateTime(@d VARCHAR(50))
RETURNS BIT
AS
BEGIN
DECLARE @bitReturnValue BIT
SELECT @bitReturnValue =CASE
WHEN ISDATE(@d) = 1 THEN CASE
WHEN CONVERT(DATETIME,@d) > ='19000101'
AND CONVERT(DATETIME,@d) <= '20790606 23:59:29.998' THEN 1
ELSE 0
END
ELSE 0
END
RETURN @bitReturnValue
END
GO
Let's create a test table with values
CREATE TABLE TestSmallDate (SomeDate VARCHAR(40))
INSERT TestSmallDate VALUES ('19000101')
INSERT TestSmallDate VALUES ('18991231')
INSERT TestSmallDate VALUES ('19010101')
INSERT TestSmallDate VALUES('20790607')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:29.677')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:29.998')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:29.999')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:59.000')
INSERT TestSmallDate VALUES('2079-06-06 01:00:00')
INSERT TestSmallDate VALUES ('2079-06-06 00:00:00')
INSERT TestSmallDate VALUES ('2079-06-06 00:00:01')
INSERT TestSmallDate VALUES('WhoIsYourDaddy')
If you want NULL for values that can not be converted to SMALLDATETIME use this code
SELECT dbo.fnIsSmallDateTime(SomeDate),
CASE dbo.fnIsSmallDateTime(SomeDate)
WHEN 1 THEN CONVERT(SMALLDATETIME,SomeDate) END AS ConvertedToSmallDate,
SomeDate
FROM TestSmallDate
if you want to convert the values that can not be converted to SMALLDATETIME to '1901-01-01 00:00:00' use the code below
SELECT dbo.fnIsSmallDateTime(SomeDate),
CASE dbo.fnIsSmallDateTime(SomeDate)
WHEN 1 THEN CONVERT(SMALLDATETIME,SomeDate)
ELSE CONVERT(SMALLDATETIME,'19000101') END AS ConvertedToSmallDate,
SomeDate
FROM TestSmallDate
Return only data that can be converted to SMALLDATETIME
SELECT * FROM TestSmallDate
WHERE dbo.fnIsSmallDateTime(SomeDate) =1
Return only data that can not converted to SMALLDATETIME
SELECT * FROM TestSmallDate
WHERE dbo.fnIsSmallDateTime(SomeDate) =0
So even though the ISDATE function returns 1 for the date 1890-01-01 this can not be converted to SMALLDATETIME and you will receive an error message after you run the following statement
SELECT CONVERT(SMALLDATETIME,'18900101')
Server: Msg 296, Level 16, State 3, Line 1
The conversion of char data type to smalldatetime data type resulted in an out-of-range smalldatetime value.
Also be careful with rounding
Run these four statements
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:29')
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:29.998')
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:29.999')
SELECT CONVERT(SMALLDATETIME,'2079-06-06 23:59:30')
The first two are fine , the second two blow up because the value gets rounded up to the next day after it gets rounded up to the next minute (and hour)
I decided to roll out my own fnIsSmallDateTime() function because who wants to write the same CASE ISDATE when Value between this and that code all over the place?
Here is the code for the user defined function
CREATE FUNCTION fnIsSmallDateTime(@d VARCHAR(50))
RETURNS BIT
AS
BEGIN
DECLARE @bitReturnValue BIT
SELECT @bitReturnValue =CASE
WHEN ISDATE(@d) = 1 THEN CASE
WHEN CONVERT(DATETIME,@d) > ='19000101'
AND CONVERT(DATETIME,@d) <= '20790606 23:59:29.998' THEN 1
ELSE 0
END
ELSE 0
END
RETURN @bitReturnValue
END
GO
Let's create a test table with values
CREATE TABLE TestSmallDate (SomeDate VARCHAR(40))
INSERT TestSmallDate VALUES ('19000101')
INSERT TestSmallDate VALUES ('18991231')
INSERT TestSmallDate VALUES ('19010101')
INSERT TestSmallDate VALUES('20790607')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:29.677')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:29.998')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:29.999')
INSERT TestSmallDate VALUES ('2079-06-06 23:59:59.000')
INSERT TestSmallDate VALUES('2079-06-06 01:00:00')
INSERT TestSmallDate VALUES ('2079-06-06 00:00:00')
INSERT TestSmallDate VALUES ('2079-06-06 00:00:01')
INSERT TestSmallDate VALUES('WhoIsYourDaddy')
If you want NULL for values that can not be converted to SMALLDATETIME use this code
SELECT dbo.fnIsSmallDateTime(SomeDate),
CASE dbo.fnIsSmallDateTime(SomeDate)
WHEN 1 THEN CONVERT(SMALLDATETIME,SomeDate) END AS ConvertedToSmallDate,
SomeDate
FROM TestSmallDate
if you want to convert the values that can not be converted to SMALLDATETIME to '1901-01-01 00:00:00' use the code below
SELECT dbo.fnIsSmallDateTime(SomeDate),
CASE dbo.fnIsSmallDateTime(SomeDate)
WHEN 1 THEN CONVERT(SMALLDATETIME,SomeDate)
ELSE CONVERT(SMALLDATETIME,'19000101') END AS ConvertedToSmallDate,
SomeDate
FROM TestSmallDate
Return only data that can be converted to SMALLDATETIME
SELECT * FROM TestSmallDate
WHERE dbo.fnIsSmallDateTime(SomeDate) =1
Return only data that can not converted to SMALLDATETIME
SELECT * FROM TestSmallDate
WHERE dbo.fnIsSmallDateTime(SomeDate) =0
SQL Server Application Platform Podcast About SQL Server Service Broker On Channel 9
Channel 9 has a two part podcast with Roger Wolter about SQL Server Service Broker. WMA, MP3 and Video formats are available for download
From the site: "You are thinking of a messaging solution for your application. A solution that can exchange messages reliably, predictably and in-order. A solution that offers queue like functionality only better. What is it you ask? None other than SQL Server 2005 and this very interesting technology known as SQL Service Broker that is built right into it. On today’s program I’m joined by my colleague Roger Wolter who is going to give us all the juicy details"
Get the episodes here --> part1, part2
From the site: "You are thinking of a messaging solution for your application. A solution that can exchange messages reliably, predictably and in-order. A solution that offers queue like functionality only better. What is it you ask? None other than SQL Server 2005 and this very interesting technology known as SQL Service Broker that is built right into it. On today’s program I’m joined by my colleague Roger Wolter who is going to give us all the juicy details"
Get the episodes here --> part1, part2
Wednesday, September 27, 2006
Cool And Sexy New SQL Server Blog
That's right! What is more cool or sexy than Query Optimizations? It doesn't matter how beautiful or complex your data model is, if you show to your boss that a query used to take 17 seconds and now runs in 300 milli-seconds then you are the new SQL superhero.
If some of the following terms are foreign to you (CTRL + K, Index Scan, Index Seek, Table Scan, Sargable, Index Hint, Parameter Sniffing, Missing Statistics, L2 Cache, Compilation, Optimal Plans) then I have the blog for you right here
Tips, Tricks, and Advice from the SQL Server Query Processing Team
Even if you do know about those terms then this is still the blog for you since there is tons of stuff that you did not know yet. so make sure to check it out and add it to your feed
If some of the following terms are foreign to you (CTRL + K, Index Scan, Index Seek, Table Scan, Sargable, Index Hint, Parameter Sniffing, Missing Statistics, L2 Cache, Compilation, Optimal Plans) then I have the blog for you right here
Tips, Tricks, and Advice from the SQL Server Query Processing Team
Even if you do know about those terms then this is still the blog for you since there is tons of stuff that you did not know yet. so make sure to check it out and add it to your feed
Subscribe to:
Posts (Atom)