This question came up the other day from a co-worker, he said he couldn't change a query but was there a way of making the same query produce a better plan by doing something else perhaps (magic?)
He said his query had a WHERE clause that looked like the following
WHERE RIGHT(SomeColumn,3) = '333'
I then asked if he could change the table, his answer was that he couldn't mess around with the current columns but he could add a column
Ok, that got me thinking about a solution, let's see what I came up with
First create the following table
USE tempdb
GO
CREATE TABLE StagingData (SomeColumn varchar(255) NOT NULL )
ALTER TABLE dbo.StagingData ADD CONSTRAINT
PK_StagingData PRIMARY KEY CLUSTERED
(
SomeColumn
) ON [PRIMARY]
GO
We will create some fake data by appending a dot and a number between 100 and 999 to a GUID
Let's insert one row so that you can see what the data will look like
DECLARE @guid uniqueidentifier
SELECT @guid = 'DEADBEEF-DEAD-BEEF-DEAD-BEEF00000075'
INSERT StagingData
SELECT CONVERT(varchar(200),@guid) + '.100'
SELECT * FROM StagingData
Output
SomeColumn
--------------------------------
DEADBEEF-DEAD-BEEF-DEAD-BEEF00000075.100
Time to insert 999,999 rows
Here is what the code looks like
INSERT StagingData
SELECT top 999999 CONVERT(varchar(200),NEWID())
+ '.'
+ CONVERT(VARCHAR(10),s2.number)
FROM master..SPT_VALUES s1
CROSS JOIN master..SPT_VALUES s2
WHERE s1.type = 'P'
AND s2.type = 'P'
and s1.number between 100 and 999
and s2.number between 100 and 999
With that completed we should now have one million rows
If we run our query to look for rows where the last 3 characters are 333 we can see that we get a scan
SET STATISTICS IO ON
GO
SELECT SomeColumn FROM StagingData
WHERE RIGHT(SomeColumn,3) = '333'
SET STATISTICS IO OFF
GO
(900 rows affected)
Table 'StagingData'. Scan count 1, logical reads 5404, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We get 900 rows back and 5404 reads
Here is what the execution plan looks like
If we always query for the last 3 characters, what we can do is add a computed column to the table that just contains the last 3 characters and then add a nonclustered index to that column
That code looks like this
ALTER TABLE StagingData ADD RightChar as RIGHT(SomeColumn,3)
GO
CREATE INDEX ix_RightChar on StagingData(RightChar)
GO
Now let's check what we get when we use this new column
SET STATISTICS IO ON
GO
SELECT SomeColumn FROM StagingData
WHERE RightChar = '333'
SET STATISTICS IO OFF
GO
(900 rows affected)
Table 'StagingData'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
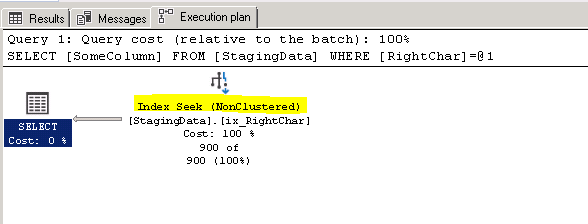
The reads went from 5404 to 10, that is a massive improvement, here is what the execution plan looks like
However there is a small problem.....
We said we would not modify the query...
What happens if we execute the same query from before? Can the SQL Server optimizer recognize that our new column and index is pretty much the same as the WHERE clause?
SET STATISTICS IO ON
GO
SELECT SomeColumn FROM StagingData
WHERE RIGHT(SomeColumn,3) = '333'
SET STATISTICS IO OFF
GO
(900 rows affected)
Table 'StagingData'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Damn right, the optimizer can, , there it is, it uses the new index and column although we specify the original column..... (must be all that AI built in... (just kidding))
If you look at the execution plan, you can see it is indeed a seek
So there you have it.. sometimes, you can't change the query, you can't mess around with existing column but you can add a column to the table, in this case a technique like the following can be beneficial
PS
Betteridge's law of headlines is an adage that states: "Any headline that ends in a question mark can be answered by the word no." It is named after Ian Betteridge, a British technology journalist who wrote about it in 2009
In this case as you can plainly see...this is not true :-) The answer to "Can adding an index make a non SARGable query SARGable?" is clearly yes