Here is an update of what I accomplished in the first 10 days
Read the book lifehacker
Read the book Microsoft SQL Server 2005 Integration Services
Read 126 pages of Extending SSIS 2005 with Script
Installed PostgreSQL, Python, Eclipse and Django.
Now you may ask yourself how I could have read all these things in 10 days. This is because I have to convert a whole bunch of packages from DTS to SSIS. So I did read a lot at work about SSIS. As you can see I sneaked the Extending SSIS 2005 with Script book in there which was not on my original list. I actually did all the example in that book. SSIS is pretty cool, the only thing which was frustrating (at first) was that you cannot modify a connection string with script like in DTS. However you can use Package Configurations to do that. This is important if you have to import a daily Excel file with a different filename every day. So as your first step in your package you just update the configuration table. Here is a small example
DECLARE @i char(8)
SELECT @i = CONVERT(CHAR(8),GETDATE()-1,112)
UPDATE dbo.[SSIS_Configurations]
SET ConfiguredValue = 'E:\SSISExcel\ida' + @i + '.csv'
WHERE ConfigurationFilter ='CSV'
AND PackagePath ='\Package.Connections[FlatFileCSV].Properties[ConnectionString]'
I will write a blogpost with more details and screenshots within the next couple of days.
I though the Microsoft SQL Server 2005 Integration Services book was pretty good. I saw some mixed reviews on Amazon but I do not agree with that at all. The book is well organized, easy to read and the examples are easy to follow. I recommend this book to anyone who has to learn SSIS.
Another book I read is lifehacker, this books shows hacks that you can use to improve your technical life. One of the hacks that I have implemented is the JunkDraw hack. You create a folder called JunkDraw, this is where you save all your downloaded content. Then there is the VB Script which is scheduled to run once a day and deletes all the files which are older than 2 weeks from this folder. So if you downloaded something and you did not move it from the folder it will be gone. How many files/apps/trial/beta apps have you downloaded, moved to a folder and never looked at again? Exactly this will prevent that kind of clutter.
I mentioned that I would like to learn a new language, so I went a little overboard because in addition to a new language I have also chosen a new database and a framework. The language is Python which was created by Guido van Rossum. Python is a scripting language and pretty popular among the FLOSS guys/girls. This of course will prepare me to play around with IronPython and the DLR once that is finalized. The DB I picked is PostgreSQL, I have chosen PostgreSQL instead of MySQL because I just can’t install a DB where you can enter invalid days. Another reason is that PostgreSQL is recommended with the framework that I picked. I picked Django over TurboGears and Ruby on Rails because I have heard some good things about it, one of them being performance. So last Sunday 5AM I installed PostgreSQL, Django, Python, Eclipse and the Eclipse Python plugin Pydev on a windows box and got the initial setup to work.
I will keep you posted on my progress once every 10 days but so far it is going good ;-)
Here is the link to the original Become a Better Developer... in 6 months article
Wednesday, July 25, 2007
This has to be one of the worst planned projects in recent Database history
http://www.tek-tips.com/viewthread.cfm?qid=1391668&page=1
here is the question
I have a situation where a person can have more then one item ordered. I need to layout the information as follows:
The information is in the same table and Item Ordered is in relationship to Person instead of Item Description.
I posted this same question on the Oracle forum, because the project is being done using two databases. Sql Server for development and Oracle for Production. I would like to get the SQL Server version of how to implement the select statement.
It gets better
Yes, it is crazy that two database are being used to develop the system, but the people who make the decisions claimed that in the preliminary stages Oracle was causing problems.
So, they switched to SQL Server as the development database. Of course the end result it that the customer expects to implement Oracle. I suspect that someone was just too lazy to learn Oracle.
And better
I asked my manager why Oracle and SQL Server and she stated that they were having load balancing issues (whatever that means). And when errors occured they were not sure how to fix them and it took too much time. At the beginning of the project there may not have been enough Oracle talent to tackle the problems. The Oracle talent available has been here for about 4 years before the project started. So, I wonder how much knowlege they DO have. I feel that an consultant should have been invested in. So, right now when stuff is put into testing for production we have to flip-flop between SQL Server and Oracle.
What? Who came up with that reason? This is just incredible. What do you think?
here is the question
I have a situation where a person can have more then one item ordered. I need to layout the information as follows:
Person Item Ordered Item Description
----------------------------------------------
1 1 of 2 Item1
1 2 of 2 Item2
2 1 of 1 Item1
3 1 of 3 Item3
3 2 of 3 Item2
3 3 of 3 Item1
.
.
The information is in the same table and Item Ordered is in relationship to Person instead of Item Description.
I posted this same question on the Oracle forum, because the project is being done using two databases. Sql Server for development and Oracle for Production. I would like to get the SQL Server version of how to implement the select statement.
It gets better
Yes, it is crazy that two database are being used to develop the system, but the people who make the decisions claimed that in the preliminary stages Oracle was causing problems.
So, they switched to SQL Server as the development database. Of course the end result it that the customer expects to implement Oracle. I suspect that someone was just too lazy to learn Oracle.
And better
I asked my manager why Oracle and SQL Server and she stated that they were having load balancing issues (whatever that means). And when errors occured they were not sure how to fix them and it took too much time. At the beginning of the project there may not have been enough Oracle talent to tackle the problems. The Oracle talent available has been here for about 4 years before the project started. So, I wonder how much knowlege they DO have. I feel that an consultant should have been invested in. So, right now when stuff is put into testing for production we have to flip-flop between SQL Server and Oracle.
What? Who came up with that reason? This is just incredible. What do you think?
Tuesday, July 24, 2007
Visual Studio Team Edition for Database Professionals Service Release 1 Is Here
Visual Studio Team Edition for Database Professionals Service Release 1 has been Released
Overview
This service release addresses the top issues that were found through feedback from customers and partners. This release includes the following features:
• Cross-database references
Support is improved to enable you to reference objects in different databases by using database project references or referencing a database metafile (.dbmeta). This support will reduce or eliminate the cross database reference warnings within a database project.
• Improved file support within SQL Server file groups
You may define files within file groups as database project properties instead of having to create files and file groups within the pre-deployment storage script.
• Variables
A Variables page is added to the database properties. This new page enables you to define setvar variables for use in the deployment scripts. Additionally, SR1 supports the latest service pack release from Microsoft SQL Server 2005 (SP2). The SR1 also supports the Windows Vista operating system.
The knowledge base (KB) article describing this service release is here http://support.microsoft.com/kb/936612/
The actual download is here:
http://www.microsoft.com/downloads/details.aspx?FamilyID=9810808c-9248-41a5-bdc1-d8210a06ed87&displaylang=en
Overview
This service release addresses the top issues that were found through feedback from customers and partners. This release includes the following features:
• Cross-database references
Support is improved to enable you to reference objects in different databases by using database project references or referencing a database metafile (.dbmeta). This support will reduce or eliminate the cross database reference warnings within a database project.
• Improved file support within SQL Server file groups
You may define files within file groups as database project properties instead of having to create files and file groups within the pre-deployment storage script.
• Variables
A Variables page is added to the database properties. This new page enables you to define setvar variables for use in the deployment scripts. Additionally, SR1 supports the latest service pack release from Microsoft SQL Server 2005 (SP2). The SR1 also supports the Windows Vista operating system.
The knowledge base (KB) article describing this service release is here http://support.microsoft.com/kb/936612/
The actual download is here:
http://www.microsoft.com/downloads/details.aspx?FamilyID=9810808c-9248-41a5-bdc1-d8210a06ed87&displaylang=en
Monday, July 23, 2007
SQL Server Podcast: James Luetkehoelter Talks About Disaster Recovery Planning
SQL Down Under has made available their latest podcast. From the site:
Announcing show 23 with SQL Server MVP James Luetkehoelter. In this show, James discusses disaster recovery planning and technology for SQL Server, clustering, log shipping, mirroring and snapshots.Dowmload it here: http://www.sqldownunder.com/
Sunday, July 22, 2007
Summer SQL Teaser #9 @@TRANCOUNT
Here is another quick teaser. What will be the values of the print statements? Try to guess it before running this code
SET
ANSI_DEFAULTS ON PRINT '#1 == ' + LTRIM(STR(@@TRANCOUNT))BEGIN
TRANSACTIONROLLBACK
Friday, July 20, 2007
Summer SQL Teaser #8 Comments And Go
Without running the following two blocks of code what do you think will the output be?
/* code 1
SELECT GETDATE()
GO */
SELECT GETDATE()
/* code 2
SELECT GETDATE()
GO
*/
SELECT GETDATE()
/* code 1
SELECT GETDATE()
GO */
SELECT GETDATE()
/* code 2
SELECT GETDATE()
GO
*/
SELECT GETDATE()
Some Pics
I have uploaded some pics on Flickr that I took a while back.
There is Paris, Amsterdam, Hawaii, Croatia and New York. Two of them you can see below. To see the NYC and Amsterdam night shots visit this URL: http://www.flickr.com/photos/denisgobo/tags/nightshot/
Amsterdam

New York city

There is Paris, Amsterdam, Hawaii, Croatia and New York. Two of them you can see below. To see the NYC and Amsterdam night shots visit this URL: http://www.flickr.com/photos/denisgobo/tags/nightshot/
Amsterdam

New York city

Thursday, July 19, 2007
The Internet has Crashed
Don't worry they got it back to work, watch the video here: http://www.scaryideas.com/video/3017/
Tuesday, July 17, 2007
Non-Technical: Happy Birthday Twins
HTML Source EditorWord wrap

Today my twins are one year old. It is supposed to be a little easier from now on (until they hit 2 that is). Here is one picture.

If you want to see more you can go here: http://www.flickr.com/photos/denisgobo/
This is the last non technical post I will make for a while, My next post will be about Scrum and planning poker.
I see that Hugo Kornelis and Adam Machanic responded to my tagging. Good, three slackers people left.
Monday, July 16, 2007
Become a Better Developer... in 6 months
I just listened to the latest Hanselminutes podcast: Be a Better Developer in Six Months
Scott Hanselman asks “what are you going to do in the next 6 months to become a better developer”?
He suggest reading books, nerd dinners, having lunches together with other non competitive companies, watch webcasts together during lunch and code reading.
Here is what I am going to do for the next 6 months
I am going to read a technical book every 10 days and review every single book
That should be possible now that my twins are one year old (tomorrow). I have a bit more free time at night to read. Here is the list of books, some of them I have read, some I have partially read.
Code Complete (reread)
I think this is one of those books that you should read once a year.
Practices of an Agile Developer
Some good stuff in here, in ordered it a couple of months ago but did not read it yet.
Inside Microsoft SQL Server 2005: T-SQL Querying (partial reread)
I read several chapters but did not read the whole book.
Inside Microsoft SQL Server 2005: The Storage Engine (reread)
I have read parts of this one; I have read the 2000 edition several times.
Refactoring (reread)
I was thinking Design Patterns (GOF) or this one. As you can see I have chosen Refactoring.
Prefactoring
Why refactor when you can prefactor? I just skimmed through it in the book store and it looks promising.
Open Sources 2.0
Open Sources 2.0 is a collection of insightful and thought-provoking essays from today's technology leaders that continues painting the evolutionary picture that developed in the 1999 book Open Sources: Voices from the Revolution.
Pragmatic Unit Testing in C# with NUnit
New edition.
Building the Data Warehouse (reread)
Read this one several years ago, will read it again
Expert SQL Server 2005 Integration Services
Will read this together with the one below at work; have to convert about 60 DTS packages to SSIS.
Microsoft SQL Server 2005 Integration Services
Beautiful Code
In this unique and insightful book, leading computer scientists offer case studies that reveal how they found unusual, carefully designed solutions to high-profile projects. You will be able to look over the shoulder of major coding and design experts to see problems through their eyes.
Pro SQL Server 2005 Database Design and Optimization (reread)
Read this will read it again
The Art of SQL
Heard some good stuff about this book.
Getting Things Done
We all need some help with organizing our lives.
Lifehacker (reread)
Getting ThingsDone for the computer person, very useful stuff inside.
Framework Design Guidelines (reread)
Very nice book, you will learn why something was done a certain way. Good tips on what to avoid and what should be done.
New language Book probably Python or Ruby( you decide)
Here is a pic of the books I have at home, the others I have at work or I still have to purchase them.

I will watch 2 web casts a week during lunch time and review those also.
I will look at high quality source code from open source projects and also from the book Beautiful Code. I will go to CodePlex to download a couple of open source projects and will study the source code
I will learn a new language (I actually got this from Ken Henderson who suggests to learn a new language every year) and rewrite one of the current applications in that language. This way I don’t have to worry about logic problems and design, I just have to translate the code.
I will learn a new technology. I am thinking either WCF or WPF
I will keep updates on Pownce (sorry folks no invites left) everyday The reason I am doing this is so that someone can call me out in case I don’t keep my promise. This is similar to stopping smoking but not telling anyone, if you do that then who knows you stopped so that they can confront you?
I know this is cheesy but I will do it anyway, I will tag 5 people I (kind of) know and I want them to tell us their plans.
Adam Machanic
Louis Davisdson
Peter DeBetta
Mladen Prajdic
Hugo Kornelis
And I will tag 5 people whose blogs I read but I don’t know them
Jeff Smith
Jason Gaylord
Jeff Altwood
Matija Lah
Ward Pond
And you the reader, what will you do in the next 6 months to become a better developer?
Cross posted from here: http://sqlblog.com/blogs/denis_gobo/archive/2007/07/16/1746.aspx
Scott Hanselman asks “what are you going to do in the next 6 months to become a better developer”?
He suggest reading books, nerd dinners, having lunches together with other non competitive companies, watch webcasts together during lunch and code reading.
Here is what I am going to do for the next 6 months
I am going to read a technical book every 10 days and review every single book
That should be possible now that my twins are one year old (tomorrow). I have a bit more free time at night to read. Here is the list of books, some of them I have read, some I have partially read.
Code Complete (reread)
I think this is one of those books that you should read once a year.
Practices of an Agile Developer
Some good stuff in here, in ordered it a couple of months ago but did not read it yet.
Inside Microsoft SQL Server 2005: T-SQL Querying (partial reread)
I read several chapters but did not read the whole book.
Inside Microsoft SQL Server 2005: The Storage Engine (reread)
I have read parts of this one; I have read the 2000 edition several times.
Refactoring (reread)
I was thinking Design Patterns (GOF) or this one. As you can see I have chosen Refactoring.
Prefactoring
Why refactor when you can prefactor? I just skimmed through it in the book store and it looks promising.
Open Sources 2.0
Open Sources 2.0 is a collection of insightful and thought-provoking essays from today's technology leaders that continues painting the evolutionary picture that developed in the 1999 book Open Sources: Voices from the Revolution.
Pragmatic Unit Testing in C# with NUnit
New edition.
Building the Data Warehouse (reread)
Read this one several years ago, will read it again
Expert SQL Server 2005 Integration Services
Will read this together with the one below at work; have to convert about 60 DTS packages to SSIS.
Microsoft SQL Server 2005 Integration Services
Beautiful Code
In this unique and insightful book, leading computer scientists offer case studies that reveal how they found unusual, carefully designed solutions to high-profile projects. You will be able to look over the shoulder of major coding and design experts to see problems through their eyes.
Pro SQL Server 2005 Database Design and Optimization (reread)
Read this will read it again
The Art of SQL
Heard some good stuff about this book.
Getting Things Done
We all need some help with organizing our lives.
Lifehacker (reread)
Getting ThingsDone for the computer person, very useful stuff inside.
Framework Design Guidelines (reread)
Very nice book, you will learn why something was done a certain way. Good tips on what to avoid and what should be done.
New language Book probably Python or Ruby( you decide)
Here is a pic of the books I have at home, the others I have at work or I still have to purchase them.

I will watch 2 web casts a week during lunch time and review those also.
I will look at high quality source code from open source projects and also from the book Beautiful Code. I will go to CodePlex to download a couple of open source projects and will study the source code
I will learn a new language (I actually got this from Ken Henderson who suggests to learn a new language every year) and rewrite one of the current applications in that language. This way I don’t have to worry about logic problems and design, I just have to translate the code.
I will learn a new technology. I am thinking either WCF or WPF
I will keep updates on Pownce (sorry folks no invites left) everyday The reason I am doing this is so that someone can call me out in case I don’t keep my promise. This is similar to stopping smoking but not telling anyone, if you do that then who knows you stopped so that they can confront you?
I know this is cheesy but I will do it anyway, I will tag 5 people I (kind of) know and I want them to tell us their plans.
Adam Machanic
Louis Davisdson
Peter DeBetta
Mladen Prajdic
Hugo Kornelis
And I will tag 5 people whose blogs I read but I don’t know them
Jeff Smith
Jason Gaylord
Jeff Altwood
Matija Lah
Ward Pond
And you the reader, what will you do in the next 6 months to become a better developer?
Cross posted from here: http://sqlblog.com/blogs/denis_gobo/archive/2007/07/16/1746.aspx
Saturday, July 14, 2007
Best Practice: Backups
What if I told you to take your latest production backup, restore it on a different machine and try using the database? Are you comfortable with that task? Do you think it will work? When was the last time you tested your backups?
Do you even have a backup?
Why am I asking all these things? Because your data is as good as your last good backup. Is your data backed up regularly? You will say “Of course it is we use [Insert expensive backup solution here] for all our enterprise backups”. Prove it, go to work on Monday and ask them to give you the latest backup. I bet out of a 100 people who ask this question to their backup team there will be several people without a backup file.
Here is another problem: three years ago the backups were taking about 1 hour. The backup started at 12 it would be done at 1, at 1:30 a job from another machine would ftp the file down. Two years later the backup takes 2 hours to complete, you didn’t realize this. Can you guess what will happen if you try to restore once of those backup that were moved by FTP? I will tell you it won’t work. What if there is no backup and you do a FTP? Oh yes the 0kb file will be created.
Where do you keep your backups?
Are you backups in the same building? If you would say yes then you have a big problem. Let me tell you a little story. I worked for a company in New York City between 2001 and 2005. This company had their office in WTC tower one. To be safe they kept their backups in WTC tower two. Well I don’t have to tell you what happened with the backup. If you do store your backup offsite (and why wouldn’t you?) make sure it is at least 100 miles away. If you don’t want to go that far from your current location then pick a location which is safe from floods, fires and not worthy to attack.
Where is your Source Code?
Do you backup your source code? Most people will say they keep it in Subversion or Visual Source Safe. But does that get backed up? What happens if your building goes up in flames? What we do is we have a full source code backup every day. In addition to that we also have differential backups every n revisions. We have jobs that create these backups and then FTP them to 3 different locations. If you have 20 developers and you lose 6 hours of work then you have lost 120 * $$ (you do the math). This is the best case scenarios. If the backup was in the building together with all the workstations then you got a lot bigger problem to deal with.
SQL developers are notorious for not using source control. They will tell you that the database backup is their source control. A source control system does not have to be expensive; we use Subversion (which is free and better than VSS). You can either use Tortoise or the plugin for Visual Studio to do your check ins.
Do you even have a backup?
Why am I asking all these things? Because your data is as good as your last good backup. Is your data backed up regularly? You will say “Of course it is we use [Insert expensive backup solution here] for all our enterprise backups”. Prove it, go to work on Monday and ask them to give you the latest backup. I bet out of a 100 people who ask this question to their backup team there will be several people without a backup file.
Here is another problem: three years ago the backups were taking about 1 hour. The backup started at 12 it would be done at 1, at 1:30 a job from another machine would ftp the file down. Two years later the backup takes 2 hours to complete, you didn’t realize this. Can you guess what will happen if you try to restore once of those backup that were moved by FTP? I will tell you it won’t work. What if there is no backup and you do a FTP? Oh yes the 0kb file will be created.
Where do you keep your backups?
Are you backups in the same building? If you would say yes then you have a big problem. Let me tell you a little story. I worked for a company in New York City between 2001 and 2005. This company had their office in WTC tower one. To be safe they kept their backups in WTC tower two. Well I don’t have to tell you what happened with the backup. If you do store your backup offsite (and why wouldn’t you?) make sure it is at least 100 miles away. If you don’t want to go that far from your current location then pick a location which is safe from floods, fires and not worthy to attack.
Where is your Source Code?
Do you backup your source code? Most people will say they keep it in Subversion or Visual Source Safe. But does that get backed up? What happens if your building goes up in flames? What we do is we have a full source code backup every day. In addition to that we also have differential backups every n revisions. We have jobs that create these backups and then FTP them to 3 different locations. If you have 20 developers and you lose 6 hours of work then you have lost 120 * $$ (you do the math). This is the best case scenarios. If the backup was in the building together with all the workstations then you got a lot bigger problem to deal with.
SQL developers are notorious for not using source control. They will tell you that the database backup is their source control. A source control system does not have to be expensive; we use Subversion (which is free and better than VSS). You can either use Tortoise or the plugin for Visual Studio to do your check ins.
DMVStats (A SQL Server 2005 Dynamic Management View Performance Data Warehouse ) Released
Over the last year, Tom Davidson has been working on a tool called DMVstats with some of his CAT colleagues. DMVstats collects performance oriented DMVs into a data warehouse, and provides a methodology called 'Waits' and 'Queues' to identify and track down performance issues. Drill-through analysis is provided by reporting services reports.
DMVStats 1.01
A SQL Server 2005 Dynamic Management View Performance Data Warehouse
Introduction
Microsoft SQL Server 2005 provides Dynamic Management Views (DMVs) to expose valuable information that you can use for performance analysis. DMVstats 1.0 is an application that can collect, analyze and report on SQL Server 2005 DMV performance data. DMVstats does not support Microsoft SQL Server 2000 and earlier versions.
Main Components
The three main components of DMVstats are:
• DMV data collection
• DMV data warehouse repository
• Analysis and reporting.
Data collection is managed by SQL Agent jobs. The DMVstats data warehouse is called DMVstatsDB. Analysis and reporting is provided by means of Reporting Services reports.
Download it here: http://www.codeplex.com/sqldmvstats/
Friday, July 13, 2007
Summer SQL Teaser Datetime Yet Again
Okay one more quick teaser
You have this date '2007-01-01 00:00:00.001'
When adding 1 or 2 milliseconds to that date what will be the result?
SELECT DATEADD(ms,1,CONVERT(datetime, '2007-01-01 00:00:00.001'))
SELECT DATEADD(ms,2,CONVERT(datetime, '2007-01-01 00:00:00.001'))
You have this date '2007-01-01 00:00:00.001'
When adding 1 or 2 milliseconds to that date what will be the result?
SELECT DATEADD(ms,1,CONVERT(datetime, '2007-01-01 00:00:00.001'))
SELECT DATEADD(ms,2,CONVERT(datetime, '2007-01-01 00:00:00.001'))
Summer SQL Teaser: Datetime
First create this table
CREATE TABLE #DateMess (SomeDate datetime)
INSERT #DateMess VALUES('20070710')
INSERT #DateMess VALUES('20070711')
INSERT #DateMess VALUES('20070712')
INSERT #DateMess VALUES('20070713')
This should be easy for most people, but not everyone knows this.
Without running the query do you know how many rows you will get back from the query
SELECT *
FROM #DateMess
WHERE SomeDate <= '2007-07-12 23:59:59.999'
I created this teaser because of a response that Celko made here:
http://groups.google.com/group/microsoft.public.sqlserver.programming/browse_thread/thread/345a73f93cf6a684/
CREATE TABLE #DateMess (SomeDate datetime)
INSERT #DateMess VALUES('20070710')
INSERT #DateMess VALUES('20070711')
INSERT #DateMess VALUES('20070712')
INSERT #DateMess VALUES('20070713')
This should be easy for most people, but not everyone knows this.
Without running the query do you know how many rows you will get back from the query
SELECT *
FROM #DateMess
WHERE SomeDate <= '2007-07-12 23:59:59.999'
I created this teaser because of a response that Celko made here:
http://groups.google.com/group/microsoft.public.sqlserver.programming/browse_thread/thread/345a73f93cf6a684/
Wednesday, July 11, 2007
Oracle Unveils Oracle Database 11g
I know a lot of us don't just work with SQL Server so I decided to share this one
Oracle today introduced Oracle(r) Database 11g, the latest release of the world's most popular database. With more than 400 features, 15 million test hours, and 36,000 person-months of development, Oracle Database 11g is the most innovative and highest quality software product Oracle have ever announced.
"Oracle Database 11g, built on 30 years of design experience, delivers the next generation of enterprise information management," said Andy Mendelsohn, senior vice president of Database Server Technologies, Oracle. "More than ever, our customers are facing the challenges of, rapid data growth, increased data integration, and data connectivity IT cost pressures. Oracle Database 10g pioneered grid computing, and more than half of Oracle customers have moved to that release. Oracle Database 11g delivers the key features our customers have asked for to accelerate broad adoption and growth of Oracle grids; representing real innovation, that addresses real challenges, as told to us by real customers."
Oracle Database 11g can help organizations take control of their enterprise information, gain better business insight, and quickly and confidently adapt to an increasingly changing competitive environment. To do this, the new release extends Oracle's unique database clustering, data center automation, and workload management capabilities. With secure, highly available and scalable grids of low-cost servers and storage, Oracle customers can tackle the most demanding transaction processing, data warehousing, and content management applications.
Real Application Testing Helps Reduce Time, Risk and Cost of Change
Oracle Database 11g features advanced self-management and automation features to help organizations meet service level agreements. For example, with organizations facing regular database and operating system software upgrades, and hardware and system changes, Oracle Database 11g introduces Oracle Real Application Testing, making it the first database to help customers test and manage changes to their IT environment quickly, in a controlled, cost effective manner.
Increase Return On Investment for Disaster Recovery Solutions
In Oracle Database 11g, Oracle Data Guard enables customers to use their standby database to improve performance in their production environments as well as provide protection from system failures and site-wide disasters. Oracle Data Guard uniquely enables simultaneous read and recovery of a single standby database making it available for reporting, backup, testing and 'rolling' upgrades to production databases. By offloading workloads from production to a standby system, Oracle Data Guard helps enhance the performance of production systems and provides a more cost-effective disaster recovery solution.
Enhanced Information Lifecycle Management and Storage Management
Oracle Database 11g has significant new data partitioning and compression capabilities, for more cost-effective Information Lifecycle Management and storage management. Oracle Database 11g automates many manual data partitioning operations and extends existing range, hash and list partitioning to include interval, reference and virtual column partitioning. In addition, Oracle Database 11g provides a complete set of composite partitioning options, allowing storage management that is driven by business rules.
Building on its long-standing data compression capabilities, Oracle Database 11g offers advanced data compression for both structured and unstructured (LOB) data managed in transaction processing, data warehousing, and content management environments. Compression ratios of 2x to 3x or more for all data can be achieved with the new advanced compression capabilities in Oracle Database 11g.
Total Recall of Data Changes
The new release also features "Oracle Total Recall," enabling administrators to query data in designated tables "as of" earlier times in the past. This offers an easy, practical way to add a time dimension to data for change tracking, auditing, and compliance.
Maximum Availability of Information
Oracle has consistently led the industry in protecting database applications from planned and unplanned downtime. Oracle Database 11g continues this lead by making it easier for administrators to meet their users' availability expectations. New availability features include Oracle Flashback Transaction which makes it easy to back out a transaction made in error, as well as any dependent transactions; Parallel Backup and Restore which helps improve the backup and restore performance of very large databases; and 'hot patching,' which improves system availability by allowing database patches to be applied without the need to shut databases down. In addition, a new advisor - Data Recovery Advisor - helps administrators significantly reduce recovery downtime by automating problem investigation, intelligently determining recovery plan and handling multiple failure situations.
Oracle Fast Files
The next-generation capability for storing large objects (LOBs) such as images, large text objects, or advanced data types � including XML, medical imaging, and three-dimensional objects - within the database. Oracle Fast Files offers database applications performance fully comparable to file systems. By storing a wider range of enterprise information and retrieving it quickly and easily, enterprises can know more about their business and adapt more rapidly.
Faster XML
Oracle Database 11g includes significant performance enhancements to XML DB, a feature of Oracle database that enables customers to natively store, and manipulate XML data. Support for binary XML has been added offering customers a choice of XML storage options to match their specific application and performance requirements. XML DB also enables manipulation of XML data using industry standard interfaces with support for XQuery, Java Specification Requests (JSR)-170 and SQL/XML standards.
Transparent Encryption
Oracle Database 11g continues to build on its unmatched security capabilities through the addition of significant enhancements. The new release features improved Oracle Transparent Data Encryption capabilities beyond column level encryption. Oracle Database 11g offers tablespace encryption that can be utilized to encrypt entire tables, indexes, and other data storage. Encryption is also provided for LOBs stored in the database.
Embedded OLAP Cubes
Oracle Database 11g also provides data warehousing innovations. OLAP cubes are enhanced to behave as materialized views in the database. This allows developers to use industry standard SQL for data query, but still benefit from the high performance delivered by an OLAP cube. New Continuous Query Notification features allow applications to be immediately notified when important changes are made to database data without burdening the database with constant polling.
Connection Pooling and Query Result Caches
The performance and scalability features in Oracle Database 11g are designed to help organizations maintain a highly performant, scalable infrastructure to provide users' with the best quality of service. Oracle Database 11g further enhances Oracle's position as the industry's performance and scalability leader with new features such as Query Result Caches which improves application performance and scalability by caching and reusing the results of often called database queries and functions in database and application tiers, and Database Resident Connection Pooling which improves the scalability of web-based systems by providing connection pooling for non-multi-threaded applications.
Enhanced Application Development
Oracle Database 11g offers developers a choice of development tools, and a streamlined application development process that takes full advantage of key Oracle Database 11g features. These include new features such as Client Side Caching, Binary XML for faster application performance, XML processing, and the storing and retrieving of files. In addition, Oracle Database 11g also includes a new Java just-in-time Compiler to execute database Java procedures faster without the need for a third party compiler; native integration with Visual Studio 2005 for developing .NET applications on Oracle; Access migration tools with Oracle Application Express; and SQL Developer easy query building feature for fast coding of SQL and PL/SQL routines.
Enhanced Self-Management and Automation
The manageability features in Oracle Database 11g are designed to help organizations easily manage enterprise grids and deliver on their users' service level expectations. Oracle Database 11g introduces more self-management and automation that will help customers reduce their system management costs, while increasing performance, scalability, availability and security of their database applications. New manageability capabilities in Oracle Database 11g include Automatic SQL and memory tuning, a new Partitioning Advisor which automatically advises administrators on how to partition tables and indexes in order to improve performance, and enhanced performance diagnostics for database clusters. In addition, Oracle Database 11g includes a new Support Workbench which provides an easy-to-use interface that presents database health-related incidents to administrators along with information on how to quickly manage the resolution of incidents.
Oracle is the #1 Database: Gartner 2006 Worldwide RDBMS Market Share Reports 47.1 Percent Share for Oracle
Gartner recently published their market share numbers by operating system for 2006 based on total software revenues. According to Gartner, Oracle:
* Has 47.1 percent share (up from 46.8 percent in 2005);
* Has revenue growth of 14.9 percent, faster than the market average of 14.2 percent with US$7.2 Billions in revenues; and,
* Continues to hold more market share than its two closest competitors combined.
About Oracle Database 11g
Oracle Database is the only database designed for grid computing. With the release of Oracle Database 11g, Oracle is making the management of enterprise information easier than ever; enabling customers to know more about their business and innovate more quickly. Oracle Database 11g delivers superior performance, scalability, availability, security and ease of management on a low-cost grid of industry standard storage and servers. Oracle Database 11g is designed to be effectively deployed on everything from small blade servers to the biggest SMP servers and clusters of all sizes. It features automated management capabilities for easy, cost-effective operation. Oracle Database 11g's unique ability to manage all data from traditional business information to XML and 3D spatial information makes it the ideal choice to power transaction processing, data warehousing, and content management applications.
Oracle today introduced Oracle(r) Database 11g, the latest release of the world's most popular database. With more than 400 features, 15 million test hours, and 36,000 person-months of development, Oracle Database 11g is the most innovative and highest quality software product Oracle have ever announced.
"Oracle Database 11g, built on 30 years of design experience, delivers the next generation of enterprise information management," said Andy Mendelsohn, senior vice president of Database Server Technologies, Oracle. "More than ever, our customers are facing the challenges of, rapid data growth, increased data integration, and data connectivity IT cost pressures. Oracle Database 10g pioneered grid computing, and more than half of Oracle customers have moved to that release. Oracle Database 11g delivers the key features our customers have asked for to accelerate broad adoption and growth of Oracle grids; representing real innovation, that addresses real challenges, as told to us by real customers."
Oracle Database 11g can help organizations take control of their enterprise information, gain better business insight, and quickly and confidently adapt to an increasingly changing competitive environment. To do this, the new release extends Oracle's unique database clustering, data center automation, and workload management capabilities. With secure, highly available and scalable grids of low-cost servers and storage, Oracle customers can tackle the most demanding transaction processing, data warehousing, and content management applications.
Real Application Testing Helps Reduce Time, Risk and Cost of Change
Oracle Database 11g features advanced self-management and automation features to help organizations meet service level agreements. For example, with organizations facing regular database and operating system software upgrades, and hardware and system changes, Oracle Database 11g introduces Oracle Real Application Testing, making it the first database to help customers test and manage changes to their IT environment quickly, in a controlled, cost effective manner.
Increase Return On Investment for Disaster Recovery Solutions
In Oracle Database 11g, Oracle Data Guard enables customers to use their standby database to improve performance in their production environments as well as provide protection from system failures and site-wide disasters. Oracle Data Guard uniquely enables simultaneous read and recovery of a single standby database making it available for reporting, backup, testing and 'rolling' upgrades to production databases. By offloading workloads from production to a standby system, Oracle Data Guard helps enhance the performance of production systems and provides a more cost-effective disaster recovery solution.
Enhanced Information Lifecycle Management and Storage Management
Oracle Database 11g has significant new data partitioning and compression capabilities, for more cost-effective Information Lifecycle Management and storage management. Oracle Database 11g automates many manual data partitioning operations and extends existing range, hash and list partitioning to include interval, reference and virtual column partitioning. In addition, Oracle Database 11g provides a complete set of composite partitioning options, allowing storage management that is driven by business rules.
Building on its long-standing data compression capabilities, Oracle Database 11g offers advanced data compression for both structured and unstructured (LOB) data managed in transaction processing, data warehousing, and content management environments. Compression ratios of 2x to 3x or more for all data can be achieved with the new advanced compression capabilities in Oracle Database 11g.
Total Recall of Data Changes
The new release also features "Oracle Total Recall," enabling administrators to query data in designated tables "as of" earlier times in the past. This offers an easy, practical way to add a time dimension to data for change tracking, auditing, and compliance.
Maximum Availability of Information
Oracle has consistently led the industry in protecting database applications from planned and unplanned downtime. Oracle Database 11g continues this lead by making it easier for administrators to meet their users' availability expectations. New availability features include Oracle Flashback Transaction which makes it easy to back out a transaction made in error, as well as any dependent transactions; Parallel Backup and Restore which helps improve the backup and restore performance of very large databases; and 'hot patching,' which improves system availability by allowing database patches to be applied without the need to shut databases down. In addition, a new advisor - Data Recovery Advisor - helps administrators significantly reduce recovery downtime by automating problem investigation, intelligently determining recovery plan and handling multiple failure situations.
Oracle Fast Files
The next-generation capability for storing large objects (LOBs) such as images, large text objects, or advanced data types � including XML, medical imaging, and three-dimensional objects - within the database. Oracle Fast Files offers database applications performance fully comparable to file systems. By storing a wider range of enterprise information and retrieving it quickly and easily, enterprises can know more about their business and adapt more rapidly.
Faster XML
Oracle Database 11g includes significant performance enhancements to XML DB, a feature of Oracle database that enables customers to natively store, and manipulate XML data. Support for binary XML has been added offering customers a choice of XML storage options to match their specific application and performance requirements. XML DB also enables manipulation of XML data using industry standard interfaces with support for XQuery, Java Specification Requests (JSR)-170 and SQL/XML standards.
Transparent Encryption
Oracle Database 11g continues to build on its unmatched security capabilities through the addition of significant enhancements. The new release features improved Oracle Transparent Data Encryption capabilities beyond column level encryption. Oracle Database 11g offers tablespace encryption that can be utilized to encrypt entire tables, indexes, and other data storage. Encryption is also provided for LOBs stored in the database.
Embedded OLAP Cubes
Oracle Database 11g also provides data warehousing innovations. OLAP cubes are enhanced to behave as materialized views in the database. This allows developers to use industry standard SQL for data query, but still benefit from the high performance delivered by an OLAP cube. New Continuous Query Notification features allow applications to be immediately notified when important changes are made to database data without burdening the database with constant polling.
Connection Pooling and Query Result Caches
The performance and scalability features in Oracle Database 11g are designed to help organizations maintain a highly performant, scalable infrastructure to provide users' with the best quality of service. Oracle Database 11g further enhances Oracle's position as the industry's performance and scalability leader with new features such as Query Result Caches which improves application performance and scalability by caching and reusing the results of often called database queries and functions in database and application tiers, and Database Resident Connection Pooling which improves the scalability of web-based systems by providing connection pooling for non-multi-threaded applications.
Enhanced Application Development
Oracle Database 11g offers developers a choice of development tools, and a streamlined application development process that takes full advantage of key Oracle Database 11g features. These include new features such as Client Side Caching, Binary XML for faster application performance, XML processing, and the storing and retrieving of files. In addition, Oracle Database 11g also includes a new Java just-in-time Compiler to execute database Java procedures faster without the need for a third party compiler; native integration with Visual Studio 2005 for developing .NET applications on Oracle; Access migration tools with Oracle Application Express; and SQL Developer easy query building feature for fast coding of SQL and PL/SQL routines.
Enhanced Self-Management and Automation
The manageability features in Oracle Database 11g are designed to help organizations easily manage enterprise grids and deliver on their users' service level expectations. Oracle Database 11g introduces more self-management and automation that will help customers reduce their system management costs, while increasing performance, scalability, availability and security of their database applications. New manageability capabilities in Oracle Database 11g include Automatic SQL and memory tuning, a new Partitioning Advisor which automatically advises administrators on how to partition tables and indexes in order to improve performance, and enhanced performance diagnostics for database clusters. In addition, Oracle Database 11g includes a new Support Workbench which provides an easy-to-use interface that presents database health-related incidents to administrators along with information on how to quickly manage the resolution of incidents.
Oracle is the #1 Database: Gartner 2006 Worldwide RDBMS Market Share Reports 47.1 Percent Share for Oracle
Gartner recently published their market share numbers by operating system for 2006 based on total software revenues. According to Gartner, Oracle:
* Has 47.1 percent share (up from 46.8 percent in 2005);
* Has revenue growth of 14.9 percent, faster than the market average of 14.2 percent with US$7.2 Billions in revenues; and,
* Continues to hold more market share than its two closest competitors combined.
About Oracle Database 11g
Oracle Database is the only database designed for grid computing. With the release of Oracle Database 11g, Oracle is making the management of enterprise information easier than ever; enabling customers to know more about their business and innovate more quickly. Oracle Database 11g delivers superior performance, scalability, availability, security and ease of management on a low-cost grid of industry standard storage and servers. Oracle Database 11g is designed to be effectively deployed on everything from small blade servers to the biggest SMP servers and clusters of all sizes. It features automated management capabilities for easy, cost-effective operation. Oracle Database 11g's unique ability to manage all data from traditional business information to XML and 3D spatial information makes it the ideal choice to power transaction processing, data warehousing, and content management applications.
Tuesday, July 10, 2007
SQL Server 2008 will launch on Feb. 27, 2008
Turner announced that Windows Server® 2008, Visual Studio® 2008 and Microsoft SQL Server™ 2008 will launch together at an event in Los Angeles on Feb. 27, 2008, kicking off hundreds of launch events around the world. As the next wave of innovation from Microsoft’s Server and Tools Business, these three products will provide a reliable and security-enhanced enterprise platform, serve as the foundation for the next generation of Web-based service applications, and broadly support virtualization and business intelligence. Windows Server 2008, SQL Server 2008 and Visual Studio 2008 represent tremendous opportunities for partners and customers, and as part of the launch wave throughout 2008, Microsoft is planning extensive and far-reaching IT pro, developer and partner outreach, including worldwide training, online and virtual events, as well as myriad resources that will be made available in the coming months to help ensure partners and customers are ready to capitalize on the new benefits offered by these products.
Read the rest here: http://www.microsoft.com/presspass/press/2007/jul07/07-10WPCDay1PartnersPR.mspx
Read the rest here: http://www.microsoft.com/presspass/press/2007/jul07/07-10WPCDay1PartnersPR.mspx
Giving Away 2 Invites For Pownce
I have 2 invites left for Pownce.
Leave me a comment here (explaining why you want/need that invite, also leave your home page URL) and send an email to sqlservercode AT gmail.com (include the home page you left in the comment) if you want one.
Best 2 comments will get the invite.
I will announce the winners tomorrow (July 11 2007) at 6AM EST
Leave me a comment here (explaining why you want/need that invite, also leave your home page URL) and send an email to sqlservercode AT gmail.com (include the home page you left in the comment) if you want one.
Best 2 comments will get the invite.
I will announce the winners tomorrow (July 11 2007) at 6AM EST
Monday, July 09, 2007
SQL Controversy: Capitalizing Keywords
Do you write code like this?
set ROWCOUNT 10
select Products.ProductName as TenMostExpensiveProducts, Products.UnitPrice
from Products
order by Products.UnitPrice desc
Or like this?
SET ROWCOUNT 10
SELECT Products.ProductName AS TenMostExpensiveProducts, Products.UnitPrice
FROM Products
ORDER BY Products.UnitPrice DESC
Do we need to capitalize the keywords, functions and statements when we have syntax coloring built into the product?
Look if you use SPUFI with DB2 I understand (see image below)
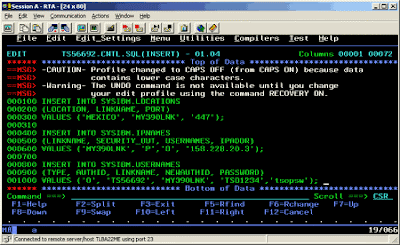
Here is another example this time without color.
set ROWCOUNT 10
select Products.ProductName as TenMostExpensiveProducts, Products.UnitPrice
from Products
order by Products.UnitPrice desc
SET ROWCOUNT 10
SELECT Products.ProductName AS TenMostExpensiveProducts, Products.UnitPrice
FROM Products
ORDER BY Products.UnitPrice DESC
And yes I agree the bottom query is much easier to read
But with syntax coloring do you still need this? It is a big pain in the neck to use that CapsLock/Shift key every time you type a keyword. There are tools of course like SQL Formatter which will make it much easier.
Remember Hungarian notation, In VB you would write sLastName(string), iCounter(integer)? Well that is gone also, who needs it when you have IntelliSense?
I think the lowercase sql code is easier on the eyes. So what do you think?
set ROWCOUNT 10
select Products.ProductName as TenMostExpensiveProducts, Products.UnitPrice
from Products
order by Products.UnitPrice desc
Or like this?
SET ROWCOUNT 10
SELECT Products.ProductName AS TenMostExpensiveProducts, Products.UnitPrice
FROM Products
ORDER BY Products.UnitPrice DESC
Do we need to capitalize the keywords, functions and statements when we have syntax coloring built into the product?
Look if you use SPUFI with DB2 I understand (see image below)

Here is another example this time without color.
set ROWCOUNT 10
select Products.ProductName as TenMostExpensiveProducts, Products.UnitPrice
from Products
order by Products.UnitPrice desc
SET ROWCOUNT 10
SELECT Products.ProductName AS TenMostExpensiveProducts, Products.UnitPrice
FROM Products
ORDER BY Products.UnitPrice DESC
And yes I agree the bottom query is much easier to read
But with syntax coloring do you still need this? It is a big pain in the neck to use that CapsLock/Shift key every time you type a keyword. There are tools of course like SQL Formatter which will make it much easier.
Remember Hungarian notation, In VB you would write sLastName(string), iCounter(integer)? Well that is gone also, who needs it when you have IntelliSense?
I think the lowercase sql code is easier on the eyes. So what do you think?
Friday, July 06, 2007
Summer SQL Teaser Non Existing Database
Here is a simple teaser, BTW I assume you don't have a database named WasabiDb or do you?
USE WasabiDb
IF @@Error <> 0
PRINT 'db doesn''t exist'
USE WasabiDb
GO
IF @@Error <> 0
PRINT 'db doesn''t exist'
If you would run this in one shot (hit F5) how many of the error messages below will you see
Server: Msg 911, Level 16, State 1, Line 1
Could not locate entry in sysdatabases for database 'WasabiDb'. No entry found with that name. Make sure that the name is entered correctly.
And how many 'db doesn't exist' messages will you see
USE WasabiDb
IF @@Error <> 0
PRINT 'db doesn''t exist'
USE WasabiDb
GO
IF @@Error <> 0
PRINT 'db doesn''t exist'
If you would run this in one shot (hit F5) how many of the error messages below will you see
Server: Msg 911, Level 16, State 1, Line 1
Could not locate entry in sysdatabases for database 'WasabiDb'. No entry found with that name. Make sure that the name is entered correctly.
And how many 'db doesn't exist' messages will you see
Wednesday, July 04, 2007
SQL Server 2005 Best Practices Analyzer Released, End Of Support For SQL Server 2000 SP3a In 6 Days
End of Support for SQL Server 2000 Service Pack 3a
Support for SQL Server 2000 Service Pack 3a (SP3a) will end on July 10, 2007.
Microsoft will end technical support on this date, which also includes security updates for this Service Pack. Microsoft is ending support for this product as part of our Service Pack support policy, found http://support.microsoft.com/lifecycle.
Customers running SQL Server 2000 Service Pack 3a are encouraged to migrate to SQL Server 2000 Service Pack 4 or SQL Server 2005. Remaining current on your service pack installation ensures that your products remain supported per the Support Lifecycle policy. Additionally, your software benefits from the many enhancements, fixes, and security updates provided through the latest service pack.
Read more here: http://blogs.msdn.com/sqlreleaseservices/archive/2007/07/02/end-of-support-for-sql-server-2000-service-pack-3a.aspx
SQL Server 2005 Best Practices Analyzer (July 2007) Realeased
It does not say CTP anywhere on this page so I assume that this is a 'production' version.
Get it here: http://www.microsoft.com/downloads/details.aspx?FamilyID=da0531e4-e94c-4991-82fa-f0e3fbd05e63&DisplayLang=en
Support for SQL Server 2000 Service Pack 3a (SP3a) will end on July 10, 2007.
Microsoft will end technical support on this date, which also includes security updates for this Service Pack. Microsoft is ending support for this product as part of our Service Pack support policy, found http://support.microsoft.com/lifecycle.
Customers running SQL Server 2000 Service Pack 3a are encouraged to migrate to SQL Server 2000 Service Pack 4 or SQL Server 2005. Remaining current on your service pack installation ensures that your products remain supported per the Support Lifecycle policy. Additionally, your software benefits from the many enhancements, fixes, and security updates provided through the latest service pack.
Read more here: http://blogs.msdn.com/sqlreleaseservices/archive/2007/07/02/end-of-support-for-sql-server-2000-service-pack-3a.aspx
SQL Server 2005 Best Practices Analyzer (July 2007) Realeased
It does not say CTP anywhere on this page so I assume that this is a 'production' version.
Get it here: http://www.microsoft.com/downloads/details.aspx?FamilyID=da0531e4-e94c-4991-82fa-f0e3fbd05e63&DisplayLang=en
SSIS Script Task In SQL Server 2008 Can Use VB Or C#
Where do I send a thank you letter? Finally we are allowed to use C# in the SQL Server Integration Services Script Task. I always wondered why SQL Server 2005 only uses VB and not C#, you can use C# in the SQLCLR but not in a Script Task. It turns out that SSIS in SQL Server 2005 uses VSA (Visual Studio for Applications) but SQL Server 2008 will use VSTA (Visual Studio Tools for Applications). Lets put these 2 right under each other.
Visual Studio for Applications
Visual Studio Tools for Applications
See the only (confusing) difference is the word Tools. So VSTA does support C#. I guess that if you come from a heavy DTS ActiveX usage background VB would be natural to you. I never felt at home with VB.NET, I switched to C# because I was also using Java and it was easier to make the switch to C#.
Enough whining from me, here are 2 screenshots that I took from the latest SQL Server 2008 June CTP. Have a nice holiday, don't overeat


Visual Studio for Applications
Visual Studio Tools for Applications
See the only (confusing) difference is the word Tools. So VSTA does support C#. I guess that if you come from a heavy DTS ActiveX usage background VB would be natural to you. I never felt at home with VB.NET, I switched to C# because I was also using Java and it was easier to make the switch to C#.
Enough whining from me, here are 2 screenshots that I took from the latest SQL Server 2008 June CTP. Have a nice holiday, don't overeat


Thursday, June 28, 2007
Guess What I Will Be Doing Tomorrow (June 29th 2007) At 6PM
Did you think I would be waiting in line like a dummy to purchase the iPhone? Wrong my friend, I will pick up a birthday cake for my wife. As a matter of fact my home is Apple free. That is right not even Quicktime is installed ;-)
Anyway why would I buy the iPhone? I checked my bill last month and I have used a whopping 6 minutes. I don’t really use my phone except for emergencies. It is good that my wife and I share the minutes, if not she would go over every month.
So are you buying an iPhone? And if yes then please tell me why?
The next post will be technical again; it will be about Scrum and Poker.
Anyway why would I buy the iPhone? I checked my bill last month and I have used a whopping 6 minutes. I don’t really use my phone except for emergencies. It is good that my wife and I share the minutes, if not she would go over every month.
So are you buying an iPhone? And if yes then please tell me why?
The next post will be technical again; it will be about Scrum and Poker.
Friday, June 22, 2007
Summer SQL Teaser #4 Nulls and Counts
First create this table
CREATE TABLE Teaser (ID int)
INSERT Teaser VALUES(1)
INSERT Teaser VALUES(2)
INSERT Teaser VALUES(1)
INSERT Teaser VALUES(2)
INSERT Teaser VALUES(NULL)
Without running this try to figure out what the result will be
SELECT COUNT(*),
COUNT(ID),
COUNT(DISTINCT ID)
FROM Teaser
For some more NULL fun you can read NULL Trouble In SQL Server Land
CREATE TABLE Teaser (ID int)
INSERT Teaser VALUES(1)
INSERT Teaser VALUES(2)
INSERT Teaser VALUES(1)
INSERT Teaser VALUES(2)
INSERT Teaser VALUES(NULL)
Without running this try to figure out what the result will be
SELECT COUNT(*),
COUNT(ID),
COUNT(DISTINCT ID)
FROM Teaser
For some more NULL fun you can read NULL Trouble In SQL Server Land
Thursday, June 21, 2007
Good Distributed Partitioned Views / Federated Databases Article
The Microsoft SQL Server Development Customer Advisory Team has a nice blog post about Distributed Partitioned Views / Federated Databases
They cover the following definitions
Definition 1: Local Partitioned View – A single table is horizontally split into multiple tables, usually all have the same structure.
Definition 2: Cross Database Partitioned View – tables are split among different databases on the same server instance
Definition 3: Distributed (across server or instance) Partitioned View. Tables participating in the view reside in different databases which reside on different servers or different instances.
Make sure you read the list of 13 items under Lessons Learned on Distributed Partitioned Views: (multiple servers involved)
Link to the article: http://blogs.msdn.com/sqlcat/archive/2007/06/20/distributed-partitioned-views-federated-databases-lessons-learned.aspx
They cover the following definitions
Definition 1: Local Partitioned View – A single table is horizontally split into multiple tables, usually all have the same structure.
Definition 2: Cross Database Partitioned View – tables are split among different databases on the same server instance
Definition 3: Distributed (across server or instance) Partitioned View. Tables participating in the view reside in different databases which reside on different servers or different instances.
Make sure you read the list of 13 items under Lessons Learned on Distributed Partitioned Views: (multiple servers involved)
Link to the article: http://blogs.msdn.com/sqlcat/archive/2007/06/20/distributed-partitioned-views-federated-databases-lessons-learned.aspx
Monday, June 18, 2007
Which SQL Server 2005 Analysis Services Book Should I Get?
Who can recommend a good SQL Server 2005 Analysis Services book?
I know SQL Server 2000 Analysis Services but did not work with SQL Server 2005 Analysis Services yet. As a matter of fact I haven’t touched Analysis Services in 2 years. I don’t need a book which explains what a start or join schema is, I know what a slowly changing dimension is, I also know the difference between a fact table, a dimension table and MOLAP/ROLAP/HOLAP.
The 2 books that I used previously are the WROX book (Professional SQL Server 2000 Data Warehousing with Analysis Services) and the MS Press Step by Step book. I remember liking both of them, are their successors as good?
The problem with the reviews on Amazon is that it doesn’t match my expectations; the WROX 2000 book only got 2.5 stars which I think is way too low. While the book is not perfect it deserves more than 2.5 stars.
Here are the 5 books I am considering
Microsoft SQL Server(TM) 2005 Analysis Services Step by Step
Delivering Business Intelligence with Microsoft SQL Server 2005
Professional SQL Server Analysis Services 2005 with MDX
Microsoft SQL Server 2005 Analysis Services
The Microsoft Data Warehouse Toolkit: With SQL Server 2005 and the Microsoft Business Intelligence Toolset
BTW I don’t need the book right now, I won’t actually start working with this until next year. If you know of a book that is coming out between now and January please let me know also.
I know SQL Server 2000 Analysis Services but did not work with SQL Server 2005 Analysis Services yet. As a matter of fact I haven’t touched Analysis Services in 2 years. I don’t need a book which explains what a start or join schema is, I know what a slowly changing dimension is, I also know the difference between a fact table, a dimension table and MOLAP/ROLAP/HOLAP.
The 2 books that I used previously are the WROX book (Professional SQL Server 2000 Data Warehousing with Analysis Services) and the MS Press Step by Step book. I remember liking both of them, are their successors as good?
The problem with the reviews on Amazon is that it doesn’t match my expectations; the WROX 2000 book only got 2.5 stars which I think is way too low. While the book is not perfect it deserves more than 2.5 stars.
Here are the 5 books I am considering
Microsoft SQL Server(TM) 2005 Analysis Services Step by Step
Delivering Business Intelligence with Microsoft SQL Server 2005
Professional SQL Server Analysis Services 2005 with MDX
Microsoft SQL Server 2005 Analysis Services
The Microsoft Data Warehouse Toolkit: With SQL Server 2005 and the Microsoft Business Intelligence Toolset
BTW I don’t need the book right now, I won’t actually start working with this until next year. If you know of a book that is coming out between now and January please let me know also.
Thursday, June 14, 2007
Book Review: Expert SQL Server 2005 Development By Adam Machanic
 If you are an advanced or intermediate SQL Server developer then this is the book for you. Adam understands real world scenarios and understands that databases are part of a bigger group in the business world. The database is usually the most important asset in an organization. All your data is in the database, you need to secure it, this is where encryption, privilege and authorization comes in. The ratio of web servers to database servers is usually many to one, it is easy to scale out with web servers however with database servers this is not so easy. This is a reason why your code needs to be optimized and designed for application concurrency.
If you are an advanced or intermediate SQL Server developer then this is the book for you. Adam understands real world scenarios and understands that databases are part of a bigger group in the business world. The database is usually the most important asset in an organization. All your data is in the database, you need to secure it, this is where encryption, privilege and authorization comes in. The ratio of web servers to database servers is usually many to one, it is easy to scale out with web servers however with database servers this is not so easy. This is a reason why your code needs to be optimized and designed for application concurrency. I recommend this book to any intermediate or advanced SQL Server developer. This book is not a book that is like the other book you have but 2 chapters are different. NO, this book contains a lot of good info which is not available in other books. I learned a lot from reading this book and you will too. Here is the breakdown of what is covered in the chapters.
Chapter 1 Software Development Methodologies for the Database World
Adam explains what Cohesion, Coupling and Encapsulation is, where the business logic should live and the balance between maintainability, performance, security and more.
Chapter 2 Testing Database Routines
This chapter is worth the price of the book by itself. You will learn how to unit test your procedures, evaluate performance counters and this chapter introduces the SQLQueryStress Performance Tool (see picture below) which will be used in other chapters. This is a very useful tool if you have to tune a query. How many times do you set statistics time and statistics IO on and off to see the reads and CPU time? This tool does it all for you, paste in your query or proc call, specify how many times you want to run it that is it. This tool will save you many stressful (pun intended) hours

Chapter 3 Errors and Exceptions
This chapter explains the different type of exceptions and how to do error handling. You will also find out what a ‘doomed transaction’ is, this is the one where you get this user friendly message: “The current transaction cannot be commited and cannot support operations that write to the log file. Roll back the transaction.”
Chapter 4 Privilege and Authorization
This chapter explains what impersonation and ownership chaining is. Also covered is how to use EXECUTE AS and how to sign procedures.
Chapter 5 Encryption
This chapter will explain encryption to you in a clear and concise matter. You will learn how to improve performance by using Message Authentication Code. The difference between symmetric and asymmetric key encryption is covered as well as all the terminology that is needed to really understand encryption.
Chapter 6 SQLCLR: Architecture and Design Considerations
What this chapter covers is SQLCLR security, why to use SQLCLR and how to enhance Service Broker Scale-Out with SQLCLR
Chapter 7 Dynamic T-SQL
You want to protect your data? Then this is something you have to read. You will learn how to deal with sql injection, why sp_executesql is much better than exec and the performance implications of parameterization and caching.
Chapter 8 Designing Systems for Application Concurrency
If you are running an OLTP system and you are suffering from blocking/locking then this is the chapter for you. Isolation levels and how they affect concurrency is explained. This chapter uses the SQLQueryStress Performance Tool to show you the difference it makes in performance when you slightly change your proc.
Chapter 9 Working with Spatial Data
Spatial data, this is what a lot of people are storing these dates, unfortunately calculating the distance between 2 points is not as easy as it seems (the earth is not flat you know ;-( ) This chapter covers a couple of ways to represent Geospatial Data.
Chapter 10 Working with Temporal Data
Dates are everywhere in the database but unfortunately a lot of people do not know how dates are stored internally and how to write efficient queries which will cause an index seek instead of a scan. Calendar tables, time zones and intervals are all covered in this chapter
Chapter 11 Trees, Hierarchies, and Graphs
The difference between Nested Set Model, Persisting Materialized Paths and Adjacency list Hierarchies are explained. There is code included that shows you how to traverse up or down the hierarchy, insert new nodes and much more.
Amazon Link: Expert SQL Server 2005 Development
I have also interviewed Adam Machanic a while back, you can find that here: Interview with Adam Machanic Author Of Expert SQL Server 2005 Development
C# IsNullOrEmpty Function In SQL Server
Mladen Prajdic has created a SQL equivalent of the C# IsNotNullOrEmpty
I looked at it and thought that there was way too much code
Here is my version which I have modified, you pass an additional parameter in to indicate whether you want blanks only to count or not
CREATE FUNCTION dbo.IsNotNullOrEmpty(@text NVARCHAR(4000),@BlanksIsEmpty bit)
RETURNS BIT
AS
BEGIN
DECLARE @ReturnValue bit
IF @BlanksIsEmpty = 0
BEGIN
SELECT @ReturnValue= SIGN(COALESCE(DATALENGTH(@text),0))
END
ELSE
BEGIN
SELECT @ReturnValue= SIGN(COALESCE(DATALENGTH(RTRIM(@text)),0))
END
RETURN @ReturnValue
END
Go
Here are some calls where we want blanks to return as empty or null
The function returns = if it is empty and 1 if it is not empty
SELECT dbo.IsNotNullOrEmpty(null,1),dbo.IsNotNullOrEmpty('azas',1),
dbo.IsNotNullOrEmpty(' ',1),dbo.IsNotNullOrEmpty('',1)
Here are some calls where we don't want blanks to return as empty or null
SELECT dbo.IsNotNullOrEmpty(null,0),dbo.IsNotNullOrEmpty('azas',0),
dbo.IsNotNullOrEmpty(' ',0),dbo.IsNotNullOrEmpty('',0)
My function is the opposite of Mladen's I check for is NOT null or empty instead of IS null or empty (easier to code it with the SIGN function)
I looked at it and thought that there was way too much code
Here is my version which I have modified, you pass an additional parameter in to indicate whether you want blanks only to count or not
CREATE FUNCTION dbo.IsNotNullOrEmpty(@text NVARCHAR(4000),@BlanksIsEmpty bit)
RETURNS BIT
AS
BEGIN
DECLARE @ReturnValue bit
IF @BlanksIsEmpty = 0
BEGIN
SELECT @ReturnValue= SIGN(COALESCE(DATALENGTH(@text),0))
END
ELSE
BEGIN
SELECT @ReturnValue= SIGN(COALESCE(DATALENGTH(RTRIM(@text)),0))
END
RETURN @ReturnValue
END
Go
Here are some calls where we want blanks to return as empty or null
The function returns = if it is empty and 1 if it is not empty
SELECT dbo.IsNotNullOrEmpty(null,1),dbo.IsNotNullOrEmpty('azas',1),
dbo.IsNotNullOrEmpty(' ',1),dbo.IsNotNullOrEmpty('',1)
Here are some calls where we don't want blanks to return as empty or null
SELECT dbo.IsNotNullOrEmpty(null,0),dbo.IsNotNullOrEmpty('azas',0),
dbo.IsNotNullOrEmpty(' ',0),dbo.IsNotNullOrEmpty('',0)
My function is the opposite of Mladen's I check for is NOT null or empty instead of IS null or empty (easier to code it with the SIGN function)
Wednesday, June 13, 2007
SQL Myth: Truncate Cannot Be Rolled Back Because It Is Not Logged
I am still amazed at how many people still think that TRUNCATE TABLE is not logged. There is some logging going on but it is minimal, here is what Books On Line says:
TRUNCATE TABLE removes the data by deallocating the data pages used to store the table's data, and only the page deallocations are recorded in the transaction log.
The DELETE statement removes rows one at a time and records an entry in the transaction log for each deleted row.
Let’s prove that we can rollback a truncate
Create this table and do the select
CREATE TABLE dbo.Enfarkulator (ID int IDENTITY PRIMARY KEY, SomeOtherCol varchar(49))
GO
INSERT dbo.Enfarkulator VALUES(1)
INSERT dbo.Enfarkulator VALUES(1)
SELECT * FROM dbo.Enfarkulator
ID SomeOtherCol
1 1
2 1
Now run this part
BEGIN TRAN
TRUNCATE TABLE dbo.Enfarkulator
SELECT * FROM dbo.Enfarkulator
ROLLBACK TRAN
ID SomeOtherCol
(0 row(s) affected)
As you can see the table was truncated, now select from the table again
SELECT * FROM dbo.Enfarkulator
ID SomeOtherCol
1 1
2 1
Yep, the data is there, proving that you can rollback a truncate and all the data will be there. There are two other major difference between truncate and delete which I will explain below.
Truncate doesn’t preserve the identity value but delete does
This is another difference between truncate and delete, truncate will reset the identity value but delete does not. Run the following code to see how that works
CREATE TABLE dbo.Enfarkulator2 (ID int IDENTITY, SomeOtherCol varchar(49))
GO
INSERT dbo.Enfarkulator2 VALUES(1)
INSERT dbo.Enfarkulator2 VALUES(1)
SELECT * FROM dbo.Enfarkulator2
SELECT * FROM dbo.Enfarkulator
DELETE dbo.Enfarkulator2
TRUNCATE TABLE dbo.Enfarkulator
INSERT dbo.Enfarkulator VALUES(1)
INSERT dbo.Enfarkulator2 VALUES(1)
SELECT * FROM dbo.Enfarkulator2
SELECT * FROM dbo.Enfarkulator
The Enfarkulator id was reset and the Enfarkulator2 id was not. In order to do the same with delete you will need to run a dbcc checkident reseed command. Here is the code for that.
DELETE dbo.Enfarkulator2
TRUNCATE TABLE dbo.Enfarkulator
DBCC CHECKIDENT (Enfarkulator2, RESEED, 0)
Now insert again and you will see that the values are the same.
INSERT dbo.Enfarkulator VALUES(1)
INSERT dbo.Enfarkulator2 VALUES(1)
SELECT * FROM dbo.Enfarkulator2
SELECT * FROM dbo.Enfarkulator
You can’t truncate tables that are referenced by a foreign key constraint.
If you have a table which is referenced by another table with a foreign key constraint then you cannot truncate that table. Here is the code for that
CREATE TABLE dbo.Enfarkulator3 (ID int IDENTITY, SomeOtherCol varchar(49))
GO
INSERT dbo.Enfarkulator3 VALUES(1)
Now let’s add the foreign key
ALTER TABLE dbo.Enfarkulator3 ADD CONSTRAINT [FK_Fark3_Fark]
FOREIGN KEY ([ID]) REFERENCES [dbo].[Enfarkulator] ([ID])
Now try to truncate.
TRUNCATE TABLE Enfarkulator
Server: Msg 4712, Level 16, State 1, Line 1
Cannot truncate table 'Enfarkulator' because it is being referenced by a FOREIGN KEY constraint.
See? You cannot do that
--Clean up time ;-)
DROP TABLE dbo.Enfarkulator3,dbo.Enfarkulator2,dbo.Enfarkulator
Cross-posted from SQLBlog! - http://www.sqlblog.com/
TRUNCATE TABLE removes the data by deallocating the data pages used to store the table's data, and only the page deallocations are recorded in the transaction log.
The DELETE statement removes rows one at a time and records an entry in the transaction log for each deleted row.
Let’s prove that we can rollback a truncate
Create this table and do the select
CREATE TABLE dbo.Enfarkulator (ID int IDENTITY PRIMARY KEY, SomeOtherCol varchar(49))
GO
INSERT dbo.Enfarkulator VALUES(1)
INSERT dbo.Enfarkulator VALUES(1)
SELECT * FROM dbo.Enfarkulator
ID SomeOtherCol
1 1
2 1
Now run this part
BEGIN TRAN
TRUNCATE TABLE dbo.Enfarkulator
SELECT * FROM dbo.Enfarkulator
ROLLBACK TRAN
ID SomeOtherCol
(0 row(s) affected)
As you can see the table was truncated, now select from the table again
SELECT * FROM dbo.Enfarkulator
ID SomeOtherCol
1 1
2 1
Yep, the data is there, proving that you can rollback a truncate and all the data will be there. There are two other major difference between truncate and delete which I will explain below.
Truncate doesn’t preserve the identity value but delete does
This is another difference between truncate and delete, truncate will reset the identity value but delete does not. Run the following code to see how that works
CREATE TABLE dbo.Enfarkulator2 (ID int IDENTITY, SomeOtherCol varchar(49))
GO
INSERT dbo.Enfarkulator2 VALUES(1)
INSERT dbo.Enfarkulator2 VALUES(1)
SELECT * FROM dbo.Enfarkulator2
SELECT * FROM dbo.Enfarkulator
DELETE dbo.Enfarkulator2
TRUNCATE TABLE dbo.Enfarkulator
INSERT dbo.Enfarkulator VALUES(1)
INSERT dbo.Enfarkulator2 VALUES(1)
SELECT * FROM dbo.Enfarkulator2
SELECT * FROM dbo.Enfarkulator
The Enfarkulator id was reset and the Enfarkulator2 id was not. In order to do the same with delete you will need to run a dbcc checkident reseed command. Here is the code for that.
DELETE dbo.Enfarkulator2
TRUNCATE TABLE dbo.Enfarkulator
DBCC CHECKIDENT (Enfarkulator2, RESEED, 0)
Now insert again and you will see that the values are the same.
INSERT dbo.Enfarkulator VALUES(1)
INSERT dbo.Enfarkulator2 VALUES(1)
SELECT * FROM dbo.Enfarkulator2
SELECT * FROM dbo.Enfarkulator
You can’t truncate tables that are referenced by a foreign key constraint.
If you have a table which is referenced by another table with a foreign key constraint then you cannot truncate that table. Here is the code for that
CREATE TABLE dbo.Enfarkulator3 (ID int IDENTITY, SomeOtherCol varchar(49))
GO
INSERT dbo.Enfarkulator3 VALUES(1)
Now let’s add the foreign key
ALTER TABLE dbo.Enfarkulator3 ADD CONSTRAINT [FK_Fark3_Fark]
FOREIGN KEY ([ID]) REFERENCES [dbo].[Enfarkulator] ([ID])
Now try to truncate.
TRUNCATE TABLE Enfarkulator
Server: Msg 4712, Level 16, State 1, Line 1
Cannot truncate table 'Enfarkulator' because it is being referenced by a FOREIGN KEY constraint.
See? You cannot do that
--Clean up time ;-)
DROP TABLE dbo.Enfarkulator3,dbo.Enfarkulator2,dbo.Enfarkulator
Cross-posted from SQLBlog! - http://www.sqlblog.com/
Friday, June 08, 2007
Three New SQL Server Best Practices Articles On TechNet
Predeployment I/O Best Practices
The I/O system is important to the performance of SQL Server. When configuring a new server for SQL Server or when adding or modifying the disk configuration of an existing system, it is good practice to determine the capacity of the I/O subsystem prior to deploying SQL Server. This white paper discusses validating and determining the capacity of an I/O subsystem. A number of tools are available for performing this type of testing. This white paper focuses on the SQLIO.exe tool, but also compares all available tools. It also covers basic I/O configuration best practices for SQL Server 2005.
On This Page
Overview
Determining I/O Capacity
Disk Configuration Best Practices & Common Pitfalls
SQLIO
Monitoring I/O Performance Using System Monitor
Conclusion
Resources
Partial Database Availability
This white paper outlines the fundamental recovery and design patterns involving the use of filegroups in implementing partial database availability in SQL Server 2005. As databases become larger and larger, the infrastructure assets and technology that provide availability become more and more important.
The database filegroups feature introduced in previous versions of SQL Server enables the use of multiple database files in order to host very large databases (VLDB) and minimize backup time. With data spanning multiple filegroups, it is possible to construct a database layout whereby failure of certain data resources do not render the entire solution unavailable. This increases the availability of solutions that use SQL Server and further reduces the surface area of failure that would render the database totally unavailable.
Comparing Tables Organized with Clustered Indexes versus Heaps
In SQL Server 2005, any table can have either clustered indexes or be organized as a heap (without a clustered index.) This white paper summarizes the advantages and disadvantages, the difference in performance characteristics, and other behaviors of tables that are ordered as lists (clustered indexes) or heaps. The performance for six distinct scenarios where DML operations are performed on these tables are measured and detailed observations presented. This white paper provides best practice recommendations on the merits of the two types of table organization, along with examples of when you might want to use one or the other.
On This Page
Introduction
Clustered Indexes and Heaps
Test Objectives
Test Methodology
Test Results and Observations
Recommendations
Appendix: Test Environment
The I/O system is important to the performance of SQL Server. When configuring a new server for SQL Server or when adding or modifying the disk configuration of an existing system, it is good practice to determine the capacity of the I/O subsystem prior to deploying SQL Server. This white paper discusses validating and determining the capacity of an I/O subsystem. A number of tools are available for performing this type of testing. This white paper focuses on the SQLIO.exe tool, but also compares all available tools. It also covers basic I/O configuration best practices for SQL Server 2005.
On This Page
Overview
Determining I/O Capacity
Disk Configuration Best Practices & Common Pitfalls
SQLIO
Monitoring I/O Performance Using System Monitor
Conclusion
Resources
Partial Database Availability
This white paper outlines the fundamental recovery and design patterns involving the use of filegroups in implementing partial database availability in SQL Server 2005. As databases become larger and larger, the infrastructure assets and technology that provide availability become more and more important.
The database filegroups feature introduced in previous versions of SQL Server enables the use of multiple database files in order to host very large databases (VLDB) and minimize backup time. With data spanning multiple filegroups, it is possible to construct a database layout whereby failure of certain data resources do not render the entire solution unavailable. This increases the availability of solutions that use SQL Server and further reduces the surface area of failure that would render the database totally unavailable.
Comparing Tables Organized with Clustered Indexes versus Heaps
In SQL Server 2005, any table can have either clustered indexes or be organized as a heap (without a clustered index.) This white paper summarizes the advantages and disadvantages, the difference in performance characteristics, and other behaviors of tables that are ordered as lists (clustered indexes) or heaps. The performance for six distinct scenarios where DML operations are performed on these tables are measured and detailed observations presented. This white paper provides best practice recommendations on the merits of the two types of table organization, along with examples of when you might want to use one or the other.
On This Page
Introduction
Clustered Indexes and Heaps
Test Objectives
Test Methodology
Test Results and Observations
Recommendations
Appendix: Test Environment
SQL Teaser NULL vs COALESCE
Without running the code, try to guess the output
DECLARE @v1 VARCHAR(3)
DECLARE @i1 INT
SELECT ISNULL(@i1, 15.00) /2,
COALESCE(@i1 , 15.00) /2,
ISNULL(@v1, 'Teaser #2'),
COALESCE(@v1, 'Teaser #2')
I hope you will use COALESCE instead of ISNULL from now on ;-)
Cross-posted from SQLBlog! - http://www.sqlblog.com/
DECLARE @v1 VARCHAR(3)
DECLARE @i1 INT
SELECT ISNULL(@i1, 15.00) /2,
COALESCE(@i1 , 15.00) /2,
ISNULL(@v1, 'Teaser #2'),
COALESCE(@v1, 'Teaser #2')
I hope you will use COALESCE instead of ISNULL from now on ;-)
Cross-posted from SQLBlog! - http://www.sqlblog.com/
Wednesday, June 06, 2007
How To Protect Yourself From Fat-Finger Sally, Crazy Bosses and Other SQL Villains
You all have been through this at least once in your life. In your shop there is this one person who likes to use Enterprise Manager as their Rapid Data Entry Application. We all know how these people operate; they delete rows, drop tables and all kinds of other funky stuff. SQL Server 2005 has DDL triggers to help you protect against these scoundrels. What about if you are still running that piece of software from the late Triassic period known as SQL Server 2000, what can help you in that case? Don’t worry I will show you a way but first I will tell you a story. About 6 years ago I worked in New York City as a consultant on a project for a nonprofit organization. I looked in the database and found this table which was named YesNoTable. I was curious I opened the table and noticed it had only 2 rows. Here is what was stored in the table.
0 no
1 yes
I dropped it immediately. 5 minutes went by and suddenly the CRM application was broken. They ran the debugger and found out a table was missing. Luckily for me it was very easy to recreate this table. And yes, we did get rid of it soon after. Now had the table be used by a view which had been created with schemabinding I would not be able to drop the table without dropping the view first. You see even I became a SQL villain one time.
What the code below does is it will loop through all the user created tables then union them all, I created a where 1 =0 WHERE clause just in case someone decides to open the view. Since a union can only have 250 selects or so, I have created the code so that you can specify how many tables per view you would like, you do that with the @UnionCount variable.
The code does print statements it does not create the views
If you run the code in the msdb database and you specify 5 as the @UnionCount your output will be this
-- ****************************
-- **** View Starts Here *****
-- ****************************
CREATE VIEW DoNotDropMe_1 WITH SCHEMABINDING
AS
SELECT 1 As Col1 FROM [dbo].[log_shipping_databases]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_monitor]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_plan_databases]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_plan_history]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_plans]
WHERE 1=0
GO
-- ****************************
-- **** View Starts Here *****
-- ****************************
CREATE VIEW DoNotDropMe_2 WITH SCHEMABINDING
AS
SELECT 1 As Col1 FROM [dbo].[RTblClassDefs]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDatabaseVersion]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDBMProps]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDBXProps]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDTMProps]
WHERE 1=0
GO
The code is not very complex if there are more tables in the DB than you specify in the @UnionCount variable then it will do them in chunks of whatever you specified, if there are less then it will do all of them in 1 view.
Below is the code, if you have any questions then feel free to leave a comment.
USE msdb
SET NOCOUNT ON
DECLARE @UnionCount int
SELECT @UnionCount = 20
IF @UnionCount > 250 OR @UnionCount <1
BEGIN
RAISERROR ('@UnionCount has to be between 1 and 250', 16, 1)
RETURN
END
SELECT identity(int,1,1) AS id,QUOTENAME(table_schema) + '.' + QUOTENAME(table_name) AS tablename
INTO #Tables
FROM information_schema.tables
WHERE table_type ='base table'
AND OBJECTPROPERTY(OBJECT_ID(table_name),'IsMSShipped') = 0
ORDER BY table_name
DECLARE @maxloop int
DECLARE @loop int
DECLARE @tablename varchar(200)
SELECT @maxloop = MAX(id)
FROM #Tables
BEGIN
DECLARE @OuterLoopCount int, @OuterLoop int
SELECT @OuterLoopCount = COUNT(*) FROM #Tables
WHERE id %@UnionCount =0
SELECT @OuterLoopCount = COALESCE(NULLIF(@OuterLoopCount,0),1)
IF (SELECT COUNT(*) FROM #Tables) % 10 <> 0
SELECT @OuterLoopCount = @OuterLoopCount +1
SELECT @OuterLoop =1
SELECT @Loop = MIN(id),@maxloop=MAX(id)
FROM #Tables WHERE ID <= @UnionCount * @OuterLoop
WHILE @OuterLoop <=@OuterLoopCount
BEGIN
SELECT @Loop = MIN(id),@maxloop=MAX(id)
FROM #Tables WHERE ID <= @UnionCount * @OuterLoop
AND id > (@UnionCount * @OuterLoop) - @UnionCount
PRINT'-- **************************** '
PRINT'-- **** View Starts Here ***** '
PRINT'-- **************************** '
PRINT 'CREATE VIEW DoNotDropMe_' + CONVERT(VARCHAR(10),@OuterLoop) + ' WITH SCHEMABINDING'+ char(10) + 'AS'
WHILE @Loop <= @maxloop
BEGIN
SELECT @tablename = tablename
FROM #Tables
WHERE id = @Loop
PRINT 'SELECT 1 As Col1 FROM ' + @tablename + char(10) + 'WHERE 1=0'
IF @Loop < @maxloop
PRINT UNION ALL'
SET @Loop = @Loop + 1
END
SET @OuterLoop = @OuterLoop + 1
PRINT 'GO'
PRINT ''
PRINT ''
END
END
DROP table #Tables
Cross-posted from SQLBlog! - http://www.sqlblog.com/
0 no
1 yes
I dropped it immediately. 5 minutes went by and suddenly the CRM application was broken. They ran the debugger and found out a table was missing. Luckily for me it was very easy to recreate this table. And yes, we did get rid of it soon after. Now had the table be used by a view which had been created with schemabinding I would not be able to drop the table without dropping the view first. You see even I became a SQL villain one time.
What the code below does is it will loop through all the user created tables then union them all, I created a where 1 =0 WHERE clause just in case someone decides to open the view. Since a union can only have 250 selects or so, I have created the code so that you can specify how many tables per view you would like, you do that with the @UnionCount variable.
The code does print statements it does not create the views
If you run the code in the msdb database and you specify 5 as the @UnionCount your output will be this
-- ****************************
-- **** View Starts Here *****
-- ****************************
CREATE VIEW DoNotDropMe_1 WITH SCHEMABINDING
AS
SELECT 1 As Col1 FROM [dbo].[log_shipping_databases]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_monitor]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_plan_databases]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_plan_history]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[log_shipping_plans]
WHERE 1=0
GO
-- ****************************
-- **** View Starts Here *****
-- ****************************
CREATE VIEW DoNotDropMe_2 WITH SCHEMABINDING
AS
SELECT 1 As Col1 FROM [dbo].[RTblClassDefs]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDatabaseVersion]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDBMProps]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDBXProps]
WHERE 1=0
UNION ALL
SELECT 1 As Col1 FROM [dbo].[RTblDTMProps]
WHERE 1=0
GO
The code is not very complex if there are more tables in the DB than you specify in the @UnionCount variable then it will do them in chunks of whatever you specified, if there are less then it will do all of them in 1 view.
Below is the code, if you have any questions then feel free to leave a comment.
USE msdb
SET NOCOUNT ON
DECLARE @UnionCount int
SELECT @UnionCount = 20
IF @UnionCount > 250 OR @UnionCount <1
BEGIN
RAISERROR ('@UnionCount has to be between 1 and 250', 16, 1)
RETURN
END
SELECT identity(int,1,1) AS id,QUOTENAME(table_schema) + '.' + QUOTENAME(table_name) AS tablename
INTO #Tables
FROM information_schema.tables
WHERE table_type ='base table'
AND OBJECTPROPERTY(OBJECT_ID(table_name),'IsMSShipped') = 0
ORDER BY table_name
DECLARE @maxloop int
DECLARE @loop int
DECLARE @tablename varchar(200)
SELECT @maxloop = MAX(id)
FROM #Tables
BEGIN
DECLARE @OuterLoopCount int, @OuterLoop int
SELECT @OuterLoopCount = COUNT(*) FROM #Tables
WHERE id %@UnionCount =0
SELECT @OuterLoopCount = COALESCE(NULLIF(@OuterLoopCount,0),1)
IF (SELECT COUNT(*) FROM #Tables) % 10 <> 0
SELECT @OuterLoopCount = @OuterLoopCount +1
SELECT @OuterLoop =1
SELECT @Loop = MIN(id),@maxloop=MAX(id)
FROM #Tables WHERE ID <= @UnionCount * @OuterLoop
WHILE @OuterLoop <=@OuterLoopCount
BEGIN
SELECT @Loop = MIN(id),@maxloop=MAX(id)
FROM #Tables WHERE ID <= @UnionCount * @OuterLoop
AND id > (@UnionCount * @OuterLoop) - @UnionCount
PRINT'-- **************************** '
PRINT'-- **** View Starts Here ***** '
PRINT'-- **************************** '
PRINT 'CREATE VIEW DoNotDropMe_' + CONVERT(VARCHAR(10),@OuterLoop) + ' WITH SCHEMABINDING'+ char(10) + 'AS'
WHILE @Loop <= @maxloop
BEGIN
SELECT @tablename = tablename
FROM #Tables
WHERE id = @Loop
PRINT 'SELECT 1 As Col1 FROM ' + @tablename + char(10) + 'WHERE 1=0'
IF @Loop < @maxloop
PRINT UNION ALL'
SET @Loop = @Loop + 1
END
SET @OuterLoop = @OuterLoop + 1
PRINT 'GO'
PRINT ''
PRINT ''
END
END
DROP table #Tables
Cross-posted from SQLBlog! - http://www.sqlblog.com/
Monday, June 04, 2007
SQL Server 2008 Is RTM (According to SERVERPROPERTY('productlevel'))
SELECT @@VERSION,
SERVERPROPERTY('productversion'),
SERVERPROPERTY('productlevel')
Microsoft SQL Server code name "Katmai" - 10.0.1019.17 (Intel X86)
May 24 2007 15:26:55 Copyright (c) 1988-2007 Microsoft Corporation
Developer Edition on Windows NT 5.1(Build 2600: Service Pack 2)
10.0.1019.17
RTM (???)
Also interesting is that the tools (SSMS) are the same as with SQL Server 2005, If you have SQL Server 2005 already installed it will skip installing those.
Okay, this is the last Katmai post....for today.....I promise.....
Cross-posted from SQLBlog! - http://www.sqlblog.com/
SERVERPROPERTY('productversion'),
SERVERPROPERTY('productlevel')
Microsoft SQL Server code name "Katmai" - 10.0.1019.17 (Intel X86)
May 24 2007 15:26:55 Copyright (c) 1988-2007 Microsoft Corporation
Developer Edition on Windows NT 5.1
10.0.1019.17
RTM (???)
Also interesting is that the tools (SSMS) are the same as with SQL Server 2005, If you have SQL Server 2005 already installed it will skip installing those.
Okay, this is the last Katmai post....for today.....I promise.....
Cross-posted from SQLBlog! - http://www.sqlblog.com/
SQL Server 2008 (Katmai) Cannot Be Installed On A PC With SQL Server 2000 On It
I tried installing the SQL Server 2008 – June CTP on one of my machines which had SQL Server 2000 installed; it does not let you do that. I guess this is the time to uninstall SQL Server 2000. That is just what I did. First thing I noticed is that MERGE statement is back. IIRC the MERGE statement was also in SQL Server 2005 Beta2 but got pull out of the RTM
Here is a small example of using MERGE from the Katmai Books On Line
Cross-posted from SQLBlog! - http://www.sqlblog.com/
Here is a small example of using MERGE from the Katmai Books On Line
MERGE FactBuyingHabits AS fbh
USING (SELECT CustomerID, ProductID, PurchaseDate FROM PurchaseRecords) AS src
ON (fbh.ProductID = src.ProductID AND fbh.CustomerID = src.CustomerID)
WHEN MATCHED THEN
UPDATE SET fbh.LastPurchaseDate = src.PurchaseDate
WHEN NOT MATCHED THEN
INSERT (CustomerID, ProductID, LastPurchaseDate)
VALUES (src.CustomerID, src.ProductID, src.PurchaseDate);Cross-posted from SQLBlog! - http://www.sqlblog.com/
SQL Server 2008 June CTP now available!
From the connect site
Preview upcoming Releases: SQL Server 2008 June CTP now available!
We are always working on something new to make SQL Server even better. We now have SQL Server 2008 June CTP available for testing.
Link doesn't work yet, check back later here: https://connect.microsoft.com/SQLServer
Preview upcoming Releases: SQL Server 2008 June CTP now available!
We are always working on something new to make SQL Server even better. We now have SQL Server 2008 June CTP available for testing.
Link doesn't work yet, check back later here: https://connect.microsoft.com/SQLServer
SQL Server 2008/Katmai Webcast
TechNet Webcast: The Next Release of Microsoft SQL Server: Overview (Level 200)
Simulcast from Microsoft Tech·Ed 2007 in Orlando, FL.
This session provides an overview of the next release of Microsoft SQL Server that is currently under development. We cover the core value proposition, major themes and scenarios, and some specific improvements. We also discuss the new development processes Microsoft is using to build this release, the release timeline, and the disclosure calendar.
More details here: http://msevents.microsoft.com/cui/WebCastEventDetails.aspx?EventID=1032341071&EventCategory=2&culture=en-US&CountryCode=US
Simulcast from Microsoft Tech·Ed 2007 in Orlando, FL.
This session provides an overview of the next release of Microsoft SQL Server that is currently under development. We cover the core value proposition, major themes and scenarios, and some specific improvements. We also discuss the new development processes Microsoft is using to build this release, the release timeline, and the disclosure calendar.
More details here: http://msevents.microsoft.com/cui/WebCastEventDetails.aspx?EventID=1032341071&EventCategory=2&culture=en-US&CountryCode=US
Sunday, June 03, 2007
Did You Know SQL Server Has A Black Box Like An Airplane?
Paul Randal writes:
Read here how to turn it on: http://blogs.msdn.com/sqlserverstorageengine/archive/2007/06/03/sql-server-s-black-box.aspx
Cross-posted from SQLBlog! - http://www.sqlblog.com/
"Kimberly mentioned that SQL Server has a 'black-box' trace, similar to an
aircraft flight-recorder, which I'd never heard of. It's an internal trace that
has the last 5MB of various trace events and it's dumped to a file when SQL
Server crashes. This can be really useful if you're troubleshooting an issue
that causing SQL Server to crash or someone or something is telling SQL Server
to shutdown and its unclear who or what is doing it."
Read here how to turn it on: http://blogs.msdn.com/sqlserverstorageengine/archive/2007/06/03/sql-server-s-black-box.aspx
Cross-posted from SQLBlog! - http://www.sqlblog.com/
Subscribe to:
Posts (Atom)