The error String or binary data would be truncated is one of the more annoying things in SQL Server. You would insert some data and you would get back the error String or binary data would be truncated. Then you would have to spend a good amount of time to see what caused the error.
I even posted about this as part of T-SQL Tuesday #86: String or binary data would be truncated
I read the SQL Server 2019 CTP 2 whitepaper and on page 17 it has the following
Improve truncation message for ETL DW scenarios—the error message ID 8152 String or binary data would be truncated is familiar to many SQL Server developers and administrators who develop or maintain data movement workloads; the error is raised during data transfers between a source and a destination with different schemas when the source data is too large to fit into the destination data type. This error message can be time-consuming to troubleshoot because of its lack of specificity. SQL Server 2019 introduces a new, more specific error message for this scenario: ID 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'. The new error message provides more context for the problem, simplifying the troubleshooting process. So that it cannot break existing applications parsing message ID 8152, this new message ID 2628 is an opt-in replacement, which can be enabled with trace flag 460.
Oh really... they fixed this? Let's take a look
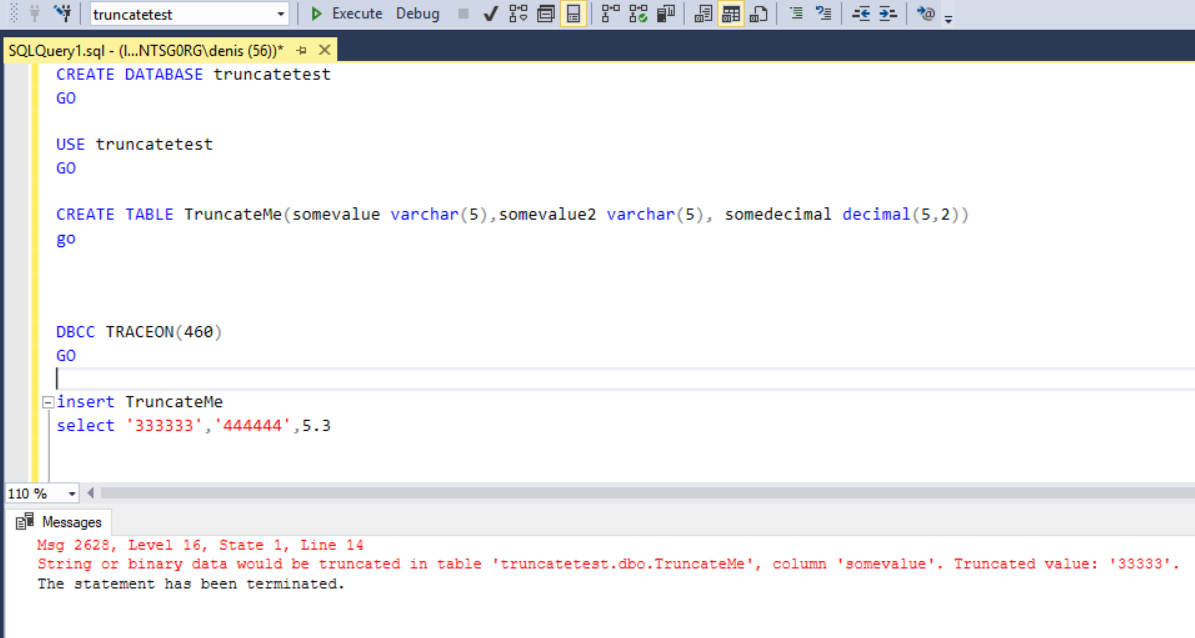
First I downloaded SQL Server 2019 CTP 2 and installed it. Then I created a database with a simple table, I also inserted some data that wouldn't fit
CREATE DATABASE truncatetest GO USE truncatetest GO CREATE TABLE TruncateMe(somevalue varchar(5),somevalue2 varchar(5), somedecimal decimal(5,2)) GO INSERT TruncateMe SELECT '333333','444444',5.3
I then received the following error message, so this is the same as in SQL Server 2018 and earlier, notice message id 8152
Msg 8152, Level 16, State 30, Line 10
String or binary data would be truncated.
The statement has been terminated.
To enable the new functionality, we need to enable trace flag 460, you can do that by running the DBCC TRACEON command like this
DBCC TRACEON(460)
Now let's try that insert statement again
INSERT TruncateMe SELECT '333333','444444',5.3
And there we go, you get the table name, the column name as well as the value, notice that the message id changed from 8152 to 2628 nowMsg 2628, Level 16, State 1, Line 20
String or binary data would be truncated in table 'truncatetest.dbo.TruncateMe', column 'somevalue'. Truncated value: '33333'.
The statement has been terminated.
So it looks it only returns the first value that generates the error, let's change the first value to fit into the column and execute the insert statement again
INSERT TruncateMe SELECT '3','444444',5.3
Now you will see that the error is for the somevalue2 columnMsg 2628, Level 16, State 1, Line 27
String or binary data would be truncated in table 'truncatetest.dbo.TruncateMe', column 'somevalue2'. Truncated value: '44444'.
The statement has been terminated.
What will happen if you have more than one row that fails?insert TruncateMe select '333333','444444',5.3 union all select '3','444444',5.3
Here is the errorMsg 2628, Level 16, State 1, Line 37
String or binary data would be truncated in table 'truncatetest.dbo.TruncateMe', column 'somevalue'. Truncated value: '33333'.
The statement has been terminated.
As you can see the error is only for the first row, not the second one
What about Table Variables, will you also get an error with the column and value like for real tables?
declare @table table (somevalue varchar(5),somevalue2 varchar(5), somedecimal decimal(5,2)) insert @table select '333333','444444',5.3
Here is the error
Msg 2628, Level 16, State 1, Line 53
String or binary data would be truncated in table 'tempdb.dbo.#A6AD698B', column 'somevalue'. Truncated value: '33333'.
As you can see you also get the error, the table name is the internal table name for the table variable tied to your session
What about Table Valued Parameters?
CREATE TYPE TestTypeTrunc AS TABLE ( somevalue varchar(5),somevalue2 varchar(5)); GO DECLARE @table TestTypeTrunc INSERT @table SELECT '555555555','444444'
Here is the error for that
Msg 2628, Level 16, State 1, Line 58
String or binary data would be truncated in table 'tempdb.dbo.#AC6642E1', column 'somevalue'. Truncated value: '55555'.
Pretty much the same message as for the table variable
I do applaud Microsoft for finally fixing this.
Here it is also in beautiful technicolor