As we finish the tumultuous 2010s and are ready for the roaring 2020s, I decided to take a quick look at the ten most viewed posts from the past decade. Two of these posts were made posted before 2010
Without any fanfare, here is the list
10. Some cool SQL Server announcements SQL Graph, Adaptive Query Plan, CTP1 of SQL vNext, SQL Injection detection
This is my recap of the chalkboard session with the SQL Server team at the SQL Server PASS summit in Seattle.
09. Convert Millisecond To "hh:mm:ss" Format
A very old post showing you how to convert from milliseconds to "hh:mm:ss" format
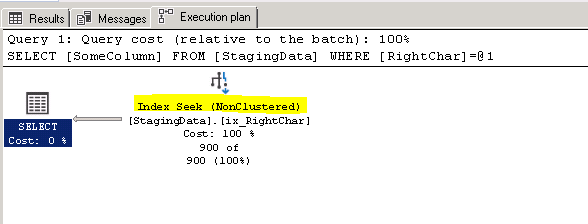
08. Can adding an index make a non SARGable query SARGable?
A post showing you how adding an index can make a query use that index even though the index column doesn't match the query
07. A little less hate for: String or binary data would be truncated in table
Can you believe they actually managed to accomplish this during the past decade :-)
06. Some numbers that you will know by heart if you have been working with SQL Server for a while
After working with SQL Server for a while, you should know most of these
05. Use T-SQL to create caveman graphs
One of the shortest post on this site, show you how you can make visually appealing output with a pipe symbol
04. Ten SQL Server Functions That You Hardly Use But Should
A very old post showing you how to convert from milliseconds to "hh:mm:ss" format
08. Can adding an index make a non SARGable query SARGable?
A post showing you how adding an index can make a query use that index even though the index column doesn't match the query
07. A little less hate for: String or binary data would be truncated in table
Can you believe they actually managed to accomplish this during the past decade :-)
06. Some numbers that you will know by heart if you have been working with SQL Server for a while
After working with SQL Server for a while, you should know most of these
05. Use T-SQL to create caveman graphs
One of the shortest post on this site, show you how you can make visually appealing output with a pipe symbol
04. Ten SQL Server Functions That You Hardly Use But Should
A post from 2007 showing some hardly used functions like NULLIF, PARSENAME and STUFF
03. Your lack of constraints is disturbing
A post showing the type of constraints available in SQL Server with examples
02. Five Ways To Return Values From Stored Procedures
A very old post that shows you five ways to return values from a stored proc
01. After 20+ years in IT .. I finally discovered this...
What can I say, read it and let me know if you knew this one....
03. Your lack of constraints is disturbing
A post showing the type of constraints available in SQL Server with examples
02. Five Ways To Return Values From Stored Procedures
A very old post that shows you five ways to return values from a stored proc
01. After 20+ years in IT .. I finally discovered this...
What can I say, read it and let me know if you knew this one....