Here are some interesting articles I read and tweeted about this past week, I think you will like these as well. If you are bored this weekend, some of these might be good for you to read
.Net 4.6.2. Framework client driver for Always Encrypted resulting in intermittent failures to decrypt individual rows
The SQL Product team has identified an issue with .Net 4.6.2 framework client driver for Always Encrypted enabled database on SQL Server 2016 and Azure SQL Database. The issue can lead to intermittent failure while trying to decrypt the records from the Always Encrypted enabled database with following error message
Decryption failed. The last 10 bytes of the encrypted column encryption key are: ‘7E-0B-E6-D3-39-CE-35-86-2F-AA’.The first 10 bytes of ciphertext are: ’01-C3-D7-39-33-2F-E6-44-C3-B1′.Specified ciphertext has an invalid authentication tag.
This paper conducts a cloud outage study of 32 popular Internet services, and analyzes outage duration, root causes, impacts, and fix procedures. The paper appeared in SOCC 2016, and the authors are Gunawi, Hao, Suminto Laksono, Satria, Adityatama, and Eliazar.
Availability is clearly very important for cloud services. Downtimes cause financial and reputation damages. As our reliance to cloud services increase, loss of availability creates even more significant problems. Yet, several outages occur in cloud services every year. The paper tries to answer why outages still take place even with pervasive redundancies.
Availability is clearly very important for cloud services. Downtimes cause financial and reputation damages. As our reliance to cloud services increase, loss of availability creates even more significant problems. Yet, several outages occur in cloud services every year. The paper tries to answer why outages still take place even with pervasive redundancies.
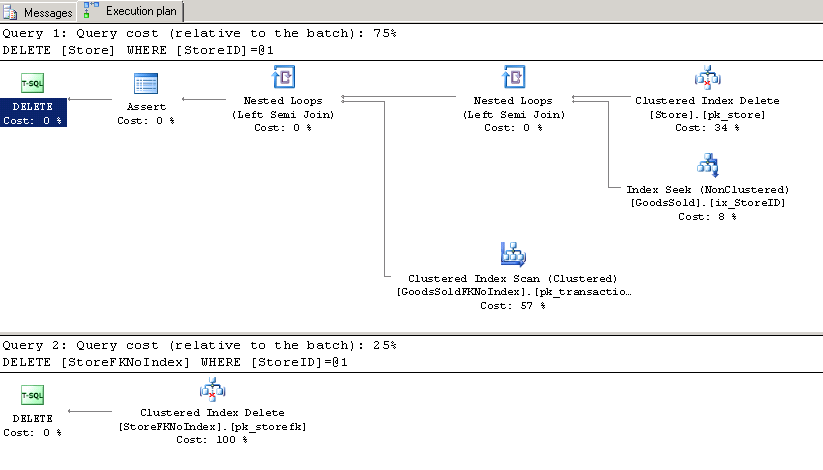
I’ve gotten a few questions about shrinking SQL Server data files lately. What’s the best way to get shrink to run? And why might it fail in some cases?
Traditionally, every time you ask a DBA how to make shrinking suck less, they start ranting how shrinking is bad and you just shouldn’t do it. Sometimes it sounds kinda angry.
What people are trying to say is that shrinking data files is generally slow, frustrating, and painful for you.
The genesis of the change began about a year and a half ago when an engineer, attempting to search "lessons learned" for relevant documents, found the number of possible results overwhelming. "He was getting things that really were not relevant to what he was looking for," David Meza, NASA’s chief knowledge architect, recalls.
Looking to make the database more useful, and help users investigate relationships beyond what basic keyword searches could uncover, Meza experimented with storing the information in a graph database—that is, a database optimized to store information in terms of data records and the connections between them. In recent years, such network graphs have become a familiar feature of online social networks.
Azure SQL Database built-in In-Memory technologies are now generally available for the Premium database tier including Premium pools. In-memory technology helps optimize the performance of transactional (OLTP), analytics (OLAP), as well as mixed workloads (HTAP). These technologies allow you to achieve phenomenal performance with Azure SQL Database – 75,000 transactions per second for order processing (11X perf gain) and reduced query execution time from 15 seconds to 0.26 (57X perf). You can also use them to reduce cost – on a P2 database obtain 9X perf gain for transactions or 10X perf gain for analytics queries by implementing In-Memory technologies, without any additional cost!
TDD Doesn't work.
It doesn't? That's odd. I've always found it to work quite well.
Not according to a new study.
Another study?
Yeah, an in-depth study that repeated another study that was done a few years back. Both showed that TDD doesn't work. The new one uses a multi-site, blind analysis, approach. It looks conclusive.
For most of these scenarios, the usual, and often the only, recovery mechanism is to restore the database from backup to a point in time just before the “oops”, known as point-in-time recovery (PITR). Even though PITR remains the most general and the most effective recovery mechanism, it does have some drawbacks and limitations: the recovery process requires a full database restore, taking the time proportional to the size of the database; a sequence of restores may be needed if multiple “oops” transactions have occurred; in the general case, there will be difficulties reconciling recovered data with data modified after the “oops” point in time, etc. Nevertheless, PITR remains the most widely applicable recovery method for SQL Server databases, both on-premises and in the cloud.
One of the most important aspects of developing smart applications is to understand the underlying machine learning models, even if you aren’t the person building them. Whether you are integrating a recommendation system into your app or building a chat bot, this guide will help you get started in understanding the basics of machine learning.
This introduction to machine learning and list of resources is adapted from my October 2016 talk at ACT-W, a women’s tech conference.
And that is all for this week, try to read some of these over the weekend....