The Metropolitan Museum of Art presents over 5,000 years of art from around the world for everyone to experience and enjoy. The Museum lives in three iconic sites in New York City—The Met Fifth Avenue, The Met Breuer, and The Met Cloisters. Millions of people also take part in The Met experience online.
Since it was founded in 1870, The Met has always aspired to be more than a treasury of rare and beautiful objects. Every day, art comes alive in the Museum's galleries and through its exhibitions and events, revealing both new ideas and unexpected connections across time and across cultures. The Metropolitan Museum of Art provides select datasets of information on more than 420,000 artworks in its Collection for unrestricted commercial and noncommercial use.
I decided to take a look. The first thing we will do is download the CSV file from their GitHub repository. You can find that here: https://github.com/metmuseum/openaccess
If you go to that link, you will see the following, grab the MetObjects.csv file
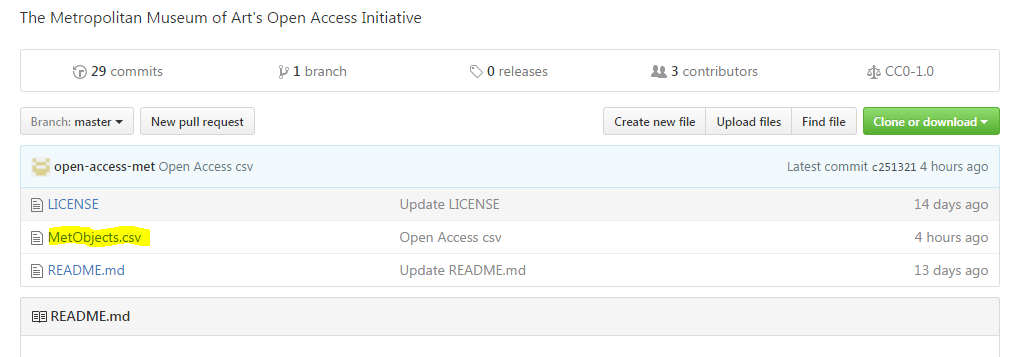
Be warned, this file is 214 MB.
One word of caution... if you try to import this file with a regular BULK INSERT command....good luck...let me know how many tries you need. No problem, I will just use a format file... and now you have 2 problems.. The real issue is that the file is somewhat problematic, there are quotes where there shouldn't be quotes, there are no quotes where there should be quotes. So what do you do?
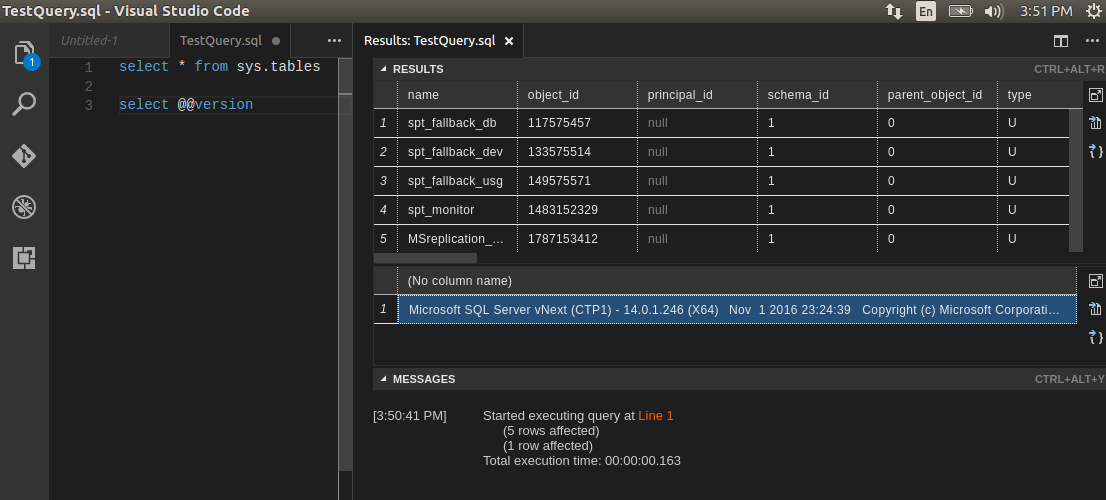
Are you on SQL Server vNext 1.1 or higher? If you are, good news, you can use BULK INSERT and csv format, this is new in vNext 1.1
Ok let's get started, first create the following table
CREATE TABLE MetOpenData( ObjectNumber nvarchar(4000), IsHighlight nvarchar(4000), IsPublicDomain nvarchar(4000), ObjectID nvarchar(4000), Department nvarchar(4000), ObjectName nvarchar(4000), Title nvarchar(4000), Culture nvarchar(4000), Period nvarchar(4000), Dynasty nvarchar(4000), Reign nvarchar(4000), Portfolio nvarchar(4000), ArtistRole nvarchar(4000), ArtistPrefix nvarchar(4000), ArtistDisplayName nvarchar(4000), ArtistDisplayBio nvarchar(4000), ArtistSuffix nvarchar(4000), ArtistAlphaSort nvarchar(4000), ArtistNationality nvarchar(4000), ArtistBeginDate nvarchar(4000), ArtistEndDate nvarchar(4000), ObjectDate nvarchar(4000), ObjectBeginDate nvarchar(4000), ObjectEndDate nvarchar(4000), Medium nvarchar(4000), Dimensions nvarchar(4000), CreditLine nvarchar(4000), GeographyType nvarchar(4000), City nvarchar(4000), State nvarchar(4000), County nvarchar(4000), Country nvarchar(4000), Region nvarchar(4000), Subregion nvarchar(4000), Locale nvarchar(4000), Locus nvarchar(4000), Excavation nvarchar(4000), River nvarchar(4000), Classification nvarchar(4000), RightsandReproduction nvarchar(4000), LinkResource nvarchar(4000), MetadataDate nvarchar(4000), Repository nvarchar(4000)) GO
Now it is time to import the file
Just to let you know, you will get a couple of errors, however all data except for these 4 rows will be imported
Msg 4864, Level 16, State 1, Line 62
Bulk load data conversion error (type mismatch or invalid character for the specified codepage) for row 213266, column 25 (Medium).
Msg 4864, Level 16, State 1, Line 62
Bulk load data conversion error (type mismatch or invalid character for the specified codepage) for row 217661, column 25 (Medium).
Msg 4863, Level 16, State 1, Line 62
Bulk load data conversion error (truncation) for row 226222, column 16 (ArtistDisplayBio).
Msg 4863, Level 16, State 1, Line 62
Bulk load data conversion error (truncation) for row 258639, column 16 (ArtistDisplayBio).
Here is what the BULK INSERT with FORMAT= 'CSV' command looks like. Change the filepath to point to the location where you have the MetObjects.csv file saved
BULK INSERT MetOpenData FROM 'c:\Data\MetObjects.csv' WITH (FORMAT = 'CSV');
Let's do a quick count
SELECT COUNT(*) FROM MetOpenData
The file that I imported resulted in 446026 rows. I downloaded this file on 2/10/2017, your file might have more data if they updated the file after the date I downloaded it
Now that we have the data we need, we can run some queries.
Let's see what kind of objects are in the collection, we will grab the top 15 objects
SELECT TOP 15 ObjectName,count(*) FROM MetOpenData GROUP BY ObjectName ORDER BY 2 DESC
Here is what the results looks like
| ObjectName | Count |
| 88582 | |
| Photograph | 28071 |
| Drawing | 24905 |
| Book | 13360 |
| Fragment | 9405 |
| Piece | 8638 |
| Negative | 6258 |
| Painting | 5862 |
| Baseball card, print | 4985 |
| Bowl | 3534 |
| Figure | 3081 |
| Baseball card | 3046 |
| Polaroid | 2706 |
| Vase | 2698 |
| Dress | 2473 |
I don't know why..but I somehow thought painting would be the most occuring object..but what do I know
You can also treat this table as you own museum catalog, let's say you want to look at van Gogh's Madame Roulin and Her Baby painting? No problem, run this query
SELECT * FROM MetOpenData WHERE ArtistDisplayName like'%van%gogh%' and title = 'Madame Roulin and Her Baby'
Scroll to the LinkResource column, you will see the following: http://www.metmuseum.org/art/collection/search/459123
Clicking on that link will give you the following

Now you can download this image and do something with it, it is after all in the public domain
Here are a couple of more queries you can play around with
SELECT city, count(*) FROM MetOpenData GROUP BY city ORDER BY 2 DESC SELECT Dynasty, count(*) FROM MetOpenData GROUP BY Dynasty ORDER BY 2 DESC SELECT Period, count(*) FROM MetOpenData GROUP BY Period ORDER BY 2 DESC SELECT ArtistNationality, count(*) FROM MetOpenData GROUP BY ArtistNationality ORDER BY 2 DESC SELECT * FROM MetOpenData WHERE ArtistDisplayName like'%pablo picasso%' SELECT * FROM MetOpenData WHERE ArtistDisplayName like'%rembrandt van rijn%' SELECT * FROM MetOpenData WHERE ObjectName like'%Postage stamps%'
I am not a big art person, but if you are and you have some interesting queries that you ran against this data please let me know in the comments
Also if you manage to get this file to import with plain old BCP or BULK INSERT with or without a format file...let me know the magic you used.... :-)