
Image by Jahobr - Own work, CC0, Link
Since today is Fibonacci day I decided to to a short post about how to do generate a Fibonacci sequence in T-SQL. But first let's take a look at what a Fibonacci sequence actually is.
In mathematics, the Fibonacci numbers are the numbers in the following integer sequence, called the Fibonacci sequence, and characterized by the fact that every number after the first two is the sum of the two preceding ones:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
Often, especially in modern usage, the sequence is extended by one more initial term:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
November 23 is celebrated as Fibonacci day because when the date is written in the mm/dd format (11/23), the digits in the date form a Fibonacci sequence: 1,1,2,3.
So here is how you can generate a Fibonacci sequence in SQL, you can do it by using s recursive table expression. Here is what it looks like if you wanted to generate the Fibonacci sequence to up to a value of 1 million
;WITH Fibonacci (Prev, Next) as ( SELECT 1, 1 UNION ALL SELECT Next, Prev + Next FROM Fibonacci WHERE Next < 1000000 ) SELECT Prev as Fibonacci FROM Fibonacci WHERE Prev < 1000000
That will generate a Fibonacci sequence that starts with 1, if you need a Fibonacci sequence that start with 0, all you have to do is replace the 1 to 0 in the first select statement
;WITH Fibonacci (Prev, Next) as ( SELECT 1, 1 UNION ALL SELECT Next, Prev + Next FROM Fibonacci WHERE Next < 1000000 ) SELECT Prev as Fibonacci FROM Fibonacci WHERE Prev < 1000000
Here is what it looks like in SSMS
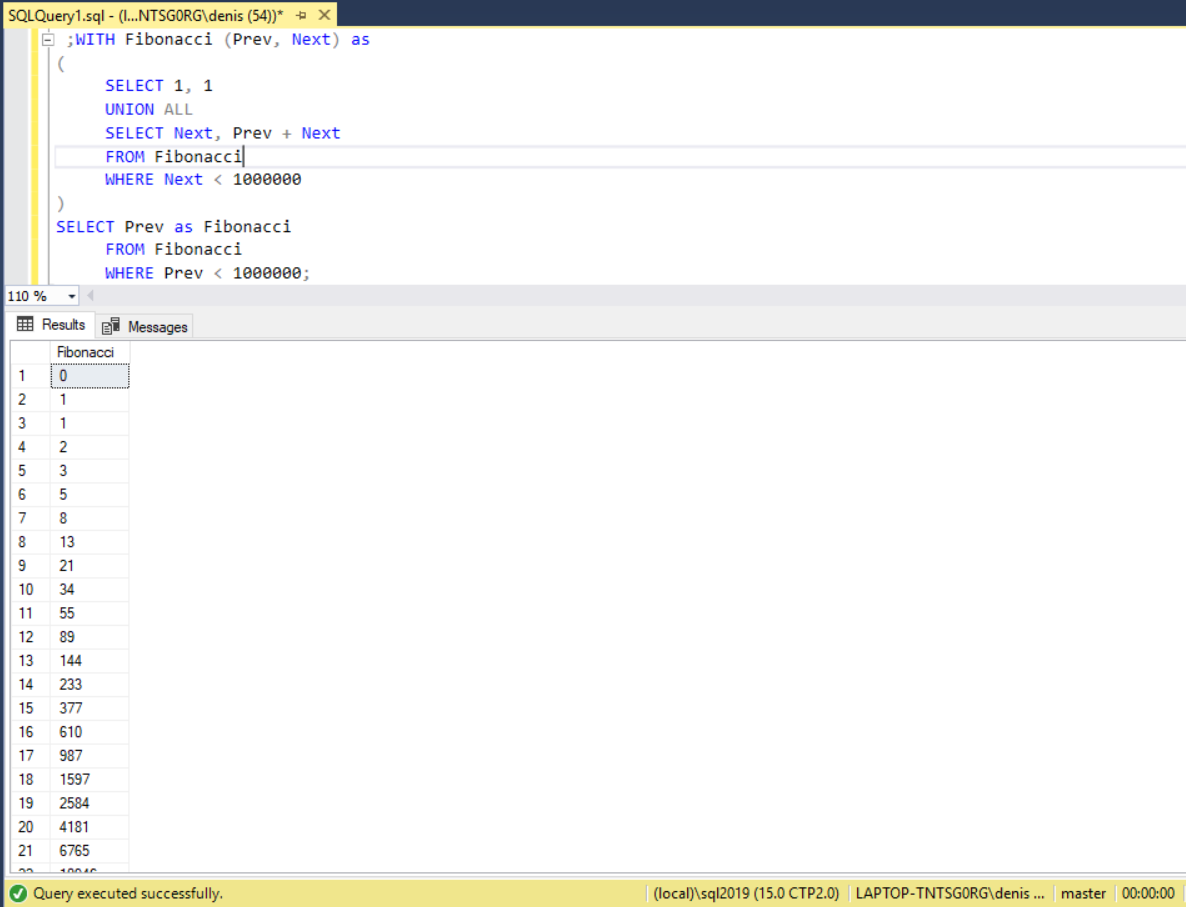
Happy Fibonacci day!!
I created the same for PostgreSQL, the only difference is that you need to add the keyword RECURSIVE in the CTE, here is that post Happy Fibonacci day, here is how to generate a Fibonacci sequence in PostgreSQL
I created the same for PostgreSQL, the only difference is that you need to add the keyword RECURSIVE in the CTE, here is that post Happy Fibonacci day, here is how to generate a Fibonacci sequence in PostgreSQL