I have seen a couple of Google searches hitting this blog with the search 'String or binary data would be truncated'
Basically what the error message 'String or binary data would be truncated' means is that the data that you are trying to fit into a column inside a table won't fit because the column isn't wide enough
A lot of times this occurs when you are inserting data into 1 table from another table
For example you have a table on some database server and you will need to import that data into a new table
You will have to store Unicode in the future so you make one of the columns nvarchar, you don't bother to check for the maximum length of the data in the original table and just make you column nvarchar(4000) (the max in SQL server 2000)
Now let's test a couple of these cases
--Create the 'original' table
CREATE TABLE TestData (ID int,
SomeValue VARCHAR(5000),
SomeOtherValue VARCHAR(6))
--add some data
INSERT INTO TestData VALUES (1,REPLICATE('A',4002),'abcdef')
INSERT INTO TestData VALUES (2,'123','abcde')
INSERT INTO TestData VALUES (3,'123','abcdef')
--Create the 'new' table
CREATE TABLE TestDataTruncate2 (ID INT,
SomeValue NVARCHAR(4000),
SomeOtherValue VARCHAR(5)) --Oops 1 less than in the original table
--Fails
INSERT INTO TestDataTruncate
SELECT * FROM TestData
WHERE ID =1
/*
Server: Msg 8152, Level 16, State 9, Line 1
String or binary data would be truncated.
The statement has been terminated.
Fails because nvarchar can only hold 4000 characters
*/
--No Problem
INSERT INTO TestDataTruncate
SELECT * FROM TestData
WHERE ID =2
--Fails
INSERT INTO TestDataTruncate
SELECT * FROM TestData
WHERE ID =3
/*
Server: Msg 8152, Level 16, State 9, Line 1
String or binary data would be truncated.
The statement has been terminated.
Fails because SomeOtherValue has 6 charaters of data
but the column is only 5 characters in the new table
*/
--Instead of opening up 2 windows and comparing the tables column by column
--you can use the query below to return all that info in a resultset
SELECT TABLE_NAME,COLUMN_NAME,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH,ORDINAL_POSITION
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME ='TestDataTruncate'
UNION ALL
SELECT TABLE_NAME,COLUMN_NAME,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH,ORDINAL_POSITION FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME ='TestData'
ORDER BY ORDINAL_POSITION,TABLE_NAME
--you can also create a self join and return only the columns
--where the name is the same but the column size is different
SELECT t1.COLUMN_NAME,t1.DATA_TYPE,
t1.CHARACTER_MAXIMUM_LENGTH,t2.CHARACTER_MAXIMUM_LENGTH,t1.ORDINAL_POSITION FROM INFORMATION_SCHEMA.COLUMNS t1
JOIN INFORMATION_SCHEMA.COLUMNS t2 ON t1.COLUMN_NAME =t2.COLUMN_NAME AND t1.TABLE_NAME <> t2.TABLE_NAME
WHERE t1.TABLE_NAME ='TestDataTruncate'
AND t2.TABLE_NAME ='TestData'
AND t1.CHARACTER_MAXIMUM_LENGTH <> t2.CHARACTER_MAXIMUM_LENGTH
--Strangely enough when you try to assign values to a variable
--it will truncate it without an error message
DECLARE @chvCity VARCHAR(8)
SELECT @chvCity ='Princeton'
SELECT @chvCity
--Clean up this mess ;-)
DROP TABLE TestDataTruncate,TestData
Thursday, May 11, 2006
Tuesday, May 09, 2006
Moved Into A New House
I have moved into a new house over the last week. If you are thinking of selling your house and buying a new one at the same time then either wait until you hit the jackpot/win the lotto or wait until your old house is paid off. This has been the most stressful experience of my life. The buyer of my house was giving me a hard time, then she couldn’t get a mortgage commitment and after that she decided to switch mortgage companies. Nothing was certain until the last millisecond. And the fact that my wife is 7 months pregnant with twins didn’t help either with this ordeal. I won’t have an internet connection until this weekend so I probably won’t post a lot this week
This post and the one that I will do after the twins are born are probably the only two non SQL related posts that will ever be on this blog, hopefully you don’t mind
This post and the one that I will do after the twins are born are probably the only two non SQL related posts that will ever be on this blog, hopefully you don’t mind
Tuesday, May 02, 2006
Top SQL Server Google Searches For April 2006
These are the top SQL Searches on this site for the month of April. I have left out searches that have nothing to do with SQL Server or programming. Here are the results...
sql server CONNECTIVITY ERRORS thro dsl after installing xp sp2
stored procedure divide
execution plans
String or binary data would be truncated
rank() performance
copy table to other server
rank() performance sql
SQL SERVER 2005 SELECT FIELD AS VARIABLE
ToBase64String sql procedure
Server: Msg 7357, Level 16, State 2, Line 1
"= isNull"
It's always interesting to see what people are searching for, I left the money laundry one in this list because I thought it was kind of amusing
I always like to look at this list so that I know what people are interested in and I can write a little thing about it
sql server CONNECTIVITY ERRORS thro dsl after installing xp sp2
stored procedure divide
execution plans
String or binary data would be truncated
rank() performance
copy table to other server
rank() performance sql
SQL SERVER 2005 SELECT FIELD AS VARIABLE
ToBase64String sql procedure
Server: Msg 7357, Level 16, State 2, Line 1
"= isNull"
It's always interesting to see what people are searching for, I left the money laundry one in this list because I thought it was kind of amusing
I always like to look at this list so that I know what people are interested in and I can write a little thing about it
Top 10 Articles Of All Time
Below are the top 10 articles of all time according to Google Analytics (updated 6/1/2006)
There is a link to it right below the Google Search box, I will update this once a month
1 SQL Query Optimizations
2 Five Ways To Return Values From Stored Procedures
3 Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
4 COALESCE And ISNULL Differences
5 SQL Server 2005 Free E-Learning
6 OPENROWSET And Excel Problems
7 Do You Know How Between Works With Dates?
8 NULL Trouble In SQL Server Land
9 Find all Primary and Foreign Keys In A Database
10 Fun With SQL Server Update Triggers
There is a link to it right below the Google Search box, I will update this once a month
1 SQL Query Optimizations
2 Five Ways To Return Values From Stored Procedures
3 Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
4 COALESCE And ISNULL Differences
5 SQL Server 2005 Free E-Learning
6 OPENROWSET And Excel Problems
7 Do You Know How Between Works With Dates?
8 NULL Trouble In SQL Server Land
9 Find all Primary and Foreign Keys In A Database
10 Fun With SQL Server Update Triggers
Top 5 SQL Server Posts For April 2006
Below are the top 5 posts according to Google Analytics for the month of April
Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
OPENROWSET And Excel Problems
SQL Query Optimizations
SQL Server 2005 Free E-Learning
Feature Pack for Microsoft SQL Server 2005
Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
OPENROWSET And Excel Problems
SQL Query Optimizations
SQL Server 2005 Free E-Learning
Feature Pack for Microsoft SQL Server 2005
A Developer’s Guide to SQL Server 2005

The follow up to the highly succesful book 'A First Look at SQL Server 2005 for Developers' has been published by Addison-Wesley
The book is 1008 pages long
From the site:
Few technologies have been as eagerly anticipated as Microsoft SQL Server 2005. Now, two SQL Server insiders deliver the definitive hands-on guide--accurate, comprehensive, and packed with examples. A Developer's Guide to SQL Server 2005 starts where Microsoft's documentation, white papers, and Web articles leave off, showing developers how to take full advantage of SQL Server 2005's key innovations. It draws on exceptional cooperation from Microsoft's SQL Server developers and the authors' extensive access to SQL Server 2005 since its earliest alpha releases.
You'll find practical explanations of the new SQL Server 2005 data model, built-in .NET hosting, improved programmability, SQL:1999 compliance, and much more. Virtually every key concept is illuminated via sample code that has been fully updated for and tested with the shipping version of the product.
Key coverage includes
Using SQL Server 2005 as a .NET runtime host: extending the server while enhancing security, reliability, and performance
Writing procedures, functions, triggers, and types in .NET languages
Exploiting enhancements to T-SQL for robust error-handling, efficient queries, and improved syntax
Effectively using the XML data type and XML queries
Implementing native SQL Server 2005 Web Services
Writing efficient, robust clients for SQL Server 2005 using ADO.NET, classic ADO, and other APIs
Taking full advantage of user-defined types (UDTs), query notifications, promotable transactions, and multiple active result sets (MARS)
Using SQL Management Objects (SMO), SQL Service Broker, and SQL Server Notification Services to build integrated applications
Download the Sample Chapter related to this title.
The Amazon link is here
Monday, May 01, 2006
Check For Not In Table Values (16 Different Ways And Counting)
How many times did you see a question like this:
how do I select all rows from a table where the column value is not 'ValueA' and not 'ValueB'
Well I decided to figure out how many different ways there are to do such a query
I came up with 16 different ways so far, some of them will cause a table scan, some of them will cause a index seek instead
You can test them out for yourself to see which ones perform the best
CREATE TABLE #TestTable (
Objects VARCHAR(20) PRIMARY KEY)
INSERT INTO #TestTable
VALUES ('boat')
INSERT INTO #TestTable
VALUES('ship')
INSERT INTO #TestTable
VALUES('car')
INSERT INTO #TestTable
VALUES('bus')
INSERT INTO #TestTable
VALUES ('airplane')
-- #1 <>
SELECT *,1
FROM #TestTable
WHERE Objects <> 'boat'
AND Objects <> 'ship'
-- #2 !=
SELECT *,2
FROM #TestTable
WHERE Objects != 'boat'
AND Objects != 'ship'
-- #3 NOT
SELECT *,3
FROM #TestTable
WHERE NOT (Objects = 'boat'
OR Objects = 'ship')
-- #4 NOT IN
SELECT *,4
FROM #TestTable
WHERE Objects NOT IN ('boat',
'ship')
-- #5 ALL
SELECT *,5
FROM #TestTable
WHERE Objects <> ALL (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #6 ANY
SELECT *,6
FROM #TestTable
WHERE NOT Objects = ANY (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #7 SOME
SELECT *,7
FROM #TestTable
WHERE NOT Objects = SOME (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #8 NOT IN with subquery
SELECT *,8
FROM #TestTable
WHERE Objects NOT IN (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #9 NOT EXISTS
SELECT *,9
FROM #TestTable T
WHERE NOT EXISTS (SELECT *
FROM (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
WHERE F.Objects = T.Objects)
-- #10 LEFT OUTER JOIN
SELECT T.*,10
FROM #TestTable T
LEFT OUTER JOIN (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
ON T.Objects = F.Objects
WHERE F.Objects IS NULL
-- #11 CHARINDEX
SELECT *,11
FROM #TestTable
WHERE CHARINDEX('-' + Objects + '-','-boat-ship-') = 0
-- #12 RIGHT OUTER JOIN
SELECT T.*,12
FROM (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
RIGHT OUTER JOIN #TestTable T
ON T.Objects = F.Objects
WHERE F.Objects IS NULL
AND T.Objects IS NOT NULL
-- #13 FULL OUTER JOIN
SELECT T.*,13
FROM (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
FULL OUTER JOIN #TestTable T
ON T.Objects = F.Objects
WHERE F.Objects IS NULL
-- #14 PATINDEX
SELECT *,14
FROM #TestTable
WHERE PATINDEX('%-%' + Objects + '%-%','-boat-ship-') = 0
-- #15 PARSENAME
SELECT *,15
FROM #TestTable
WHERE Objects <> PARSENAME('boat.ship',1)
AND Objects <> PARSENAME('boat.ship',2)
-- #16 REVERSE and NOT IN
SELECT *,16
FROM #TestTable
WHERE REVERSE(Objects) NOT IN ('taob','pihs')
-- And here is another one that BugsBunny suggested in a comment
-- #17 NOT LIKE
SELECT *,17
FROM #TestTable
WHERE ',' + 'boat,ship' + ',' NOT LIKE '%,' + Objects + ',%'
DROP TABLE #TestTable
So that's it, if you know of another way, leave me a comment or email me and I will add it to this list
how do I select all rows from a table where the column value is not 'ValueA' and not 'ValueB'
Well I decided to figure out how many different ways there are to do such a query
I came up with 16 different ways so far, some of them will cause a table scan, some of them will cause a index seek instead
You can test them out for yourself to see which ones perform the best
CREATE TABLE #TestTable (
Objects VARCHAR(20) PRIMARY KEY)
INSERT INTO #TestTable
VALUES ('boat')
INSERT INTO #TestTable
VALUES('ship')
INSERT INTO #TestTable
VALUES('car')
INSERT INTO #TestTable
VALUES('bus')
INSERT INTO #TestTable
VALUES ('airplane')
-- #1 <>
SELECT *,1
FROM #TestTable
WHERE Objects <> 'boat'
AND Objects <> 'ship'
-- #2 !=
SELECT *,2
FROM #TestTable
WHERE Objects != 'boat'
AND Objects != 'ship'
-- #3 NOT
SELECT *,3
FROM #TestTable
WHERE NOT (Objects = 'boat'
OR Objects = 'ship')
-- #4 NOT IN
SELECT *,4
FROM #TestTable
WHERE Objects NOT IN ('boat',
'ship')
-- #5 ALL
SELECT *,5
FROM #TestTable
WHERE Objects <> ALL (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #6 ANY
SELECT *,6
FROM #TestTable
WHERE NOT Objects = ANY (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #7 SOME
SELECT *,7
FROM #TestTable
WHERE NOT Objects = SOME (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #8 NOT IN with subquery
SELECT *,8
FROM #TestTable
WHERE Objects NOT IN (SELECT 'boat'
UNION ALL
SELECT 'ship')
-- #9 NOT EXISTS
SELECT *,9
FROM #TestTable T
WHERE NOT EXISTS (SELECT *
FROM (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
WHERE F.Objects = T.Objects)
-- #10 LEFT OUTER JOIN
SELECT T.*,10
FROM #TestTable T
LEFT OUTER JOIN (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
ON T.Objects = F.Objects
WHERE F.Objects IS NULL
-- #11 CHARINDEX
SELECT *,11
FROM #TestTable
WHERE CHARINDEX('-' + Objects + '-','-boat-ship-') = 0
-- #12 RIGHT OUTER JOIN
SELECT T.*,12
FROM (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
RIGHT OUTER JOIN #TestTable T
ON T.Objects = F.Objects
WHERE F.Objects IS NULL
AND T.Objects IS NOT NULL
-- #13 FULL OUTER JOIN
SELECT T.*,13
FROM (SELECT 'boat' AS Objects
UNION ALL
SELECT 'ship') F
FULL OUTER JOIN #TestTable T
ON T.Objects = F.Objects
WHERE F.Objects IS NULL
-- #14 PATINDEX
SELECT *,14
FROM #TestTable
WHERE PATINDEX('%-%' + Objects + '%-%','-boat-ship-') = 0
-- #15 PARSENAME
SELECT *,15
FROM #TestTable
WHERE Objects <> PARSENAME('boat.ship',1)
AND Objects <> PARSENAME('boat.ship',2)
-- #16 REVERSE and NOT IN
SELECT *,16
FROM #TestTable
WHERE REVERSE(Objects) NOT IN ('taob','pihs')
-- And here is another one that BugsBunny suggested in a comment
-- #17 NOT LIKE
SELECT *,17
FROM #TestTable
WHERE ',' + 'boat,ship' + ',' NOT LIKE '%,' + Objects + ',%'
DROP TABLE #TestTable
So that's it, if you know of another way, leave me a comment or email me and I will add it to this list
Friday, April 28, 2006
Splitting City, State and Zipcode From One Column (Or Flat file)
Sometimes you deal with vendors, customers or agencies and you have to do a file exchange
Of course the format of these files is always dictated by these people so what do you do when a CityStateZip column contains values like “Long Island City, NY 10013” or like “Princeton,NJ 08536 “? But in your Database it is normalized of course, and you have 3 columns. You will have to use a combination of LEFT, LTRIM, SUBSTRING, REPLACE and RIGHT. I am taking into account that there could be spaces in the column or even spaces in the name (New York City) So let’s get started and see what we get
CREATE TABLE #TestCityStateZip (csz CHAR(49))
INSERT INTO #TestCityStateZip VALUES ('city ,st 12223')
INSERT INTO #TestCityStateZip VALUES ('New York City,NY 10028')
INSERT INTO #TestCityStateZip VALUES ('Princeton , NJ 08536')
INSERT INTO #TestCityStateZip VALUES ('Princeton,NJ 08536 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City , NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City ,NY 10013 ')
SELECT LEFT(csz,CHARINDEX(',',csz)-1)AS City,
LEFT(LTRIM(SUBSTRING(csz,(CHARINDEX(',',csz)+1),4)),2) AS State,
RIGHT(RTRIM(csz),CHARINDEX(' ',REVERSE(RTRIM(csz)))-1) AS Zip
FROM #TestCityStateZip
GO
Of course the format of these files is always dictated by these people so what do you do when a CityStateZip column contains values like “Long Island City, NY 10013” or like “Princeton,NJ 08536 “? But in your Database it is normalized of course, and you have 3 columns. You will have to use a combination of LEFT, LTRIM, SUBSTRING, REPLACE and RIGHT. I am taking into account that there could be spaces in the column or even spaces in the name (New York City) So let’s get started and see what we get
CREATE TABLE #TestCityStateZip (csz CHAR(49))
INSERT INTO #TestCityStateZip VALUES ('city ,st 12223')
INSERT INTO #TestCityStateZip VALUES ('New York City,NY 10028')
INSERT INTO #TestCityStateZip VALUES ('Princeton , NJ 08536')
INSERT INTO #TestCityStateZip VALUES ('Princeton,NJ 08536 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City , NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City ,NY 10013 ')
SELECT LEFT(csz,CHARINDEX(',',csz)-1)AS City,
LEFT(LTRIM(SUBSTRING(csz,(CHARINDEX(',',csz)+1),4)),2) AS State,
RIGHT(RTRIM(csz),CHARINDEX(' ',REVERSE(RTRIM(csz)))-1) AS Zip
FROM #TestCityStateZip
GO
Tuesday, April 25, 2006
SQL Server 2005 SP1 Books Online (April 2006) For Download
SQL Server 2005 SP1 Books Online (April 2006) is available for download
Download an updated version of Books Online for Microsoft SQL Server 2005. Books Online is the primary documentation for SQL Server 2005. The April 2006 update to Books Online contains new material and fixes to documentation problems reported by customers after SQL Server 2005 was released. Refer to "New and Updated Books Online Topics" for a list of topics that are new or updated in this version. Topics with significant updates have a Change History table at the bottom of the topic that summarizes the changes. Beginning with the April 2006 update, SQL Server 2005 Books Online reflects product upgrades included in SQL Server 2005 Service Pack 1 (SP1).
The download is 121 MB
http://www.microsoft.com/downloads/details.aspx?FamilyID=be6a2c5d-00df-4220-b133-29c1e0b6585f&DisplayLang=en
Download an updated version of Books Online for Microsoft SQL Server 2005. Books Online is the primary documentation for SQL Server 2005. The April 2006 update to Books Online contains new material and fixes to documentation problems reported by customers after SQL Server 2005 was released. Refer to "New and Updated Books Online Topics" for a list of topics that are new or updated in this version. Topics with significant updates have a Change History table at the bottom of the topic that summarizes the changes. Beginning with the April 2006 update, SQL Server 2005 Books Online reflects product upgrades included in SQL Server 2005 Service Pack 1 (SP1).
The download is 121 MB
http://www.microsoft.com/downloads/details.aspx?FamilyID=be6a2c5d-00df-4220-b133-29c1e0b6585f&DisplayLang=en
Monday, April 24, 2006
How To Script Multiple Jobs Or Stored Procedures In SQL Server 2005 Management Studio
One of the biggest complaints of people who moved from SQL server 2000 to SQL Server 2005 is the inability to script multiple objects. Well that feature is still available only it’s kind of hidden
Click the Jobs or Stored Procedures folder in SQL Server Management Studio, and then hit the F7 key; this will bring up the Summary pane. Highlight all the Jobs or Stored Procedures that you want to script using a combination of Shift and Ctrl keys, then right click, Script Job/Stored Procedure as..., and then choose where to save this script to. An image of how to script Stored Procedures is below

Click the Jobs or Stored Procedures folder in SQL Server Management Studio, and then hit the F7 key; this will bring up the Summary pane. Highlight all the Jobs or Stored Procedures that you want to script using a combination of Shift and Ctrl keys, then right click, Script Job/Stored Procedure as..., and then choose where to save this script to. An image of how to script Stored Procedures is below
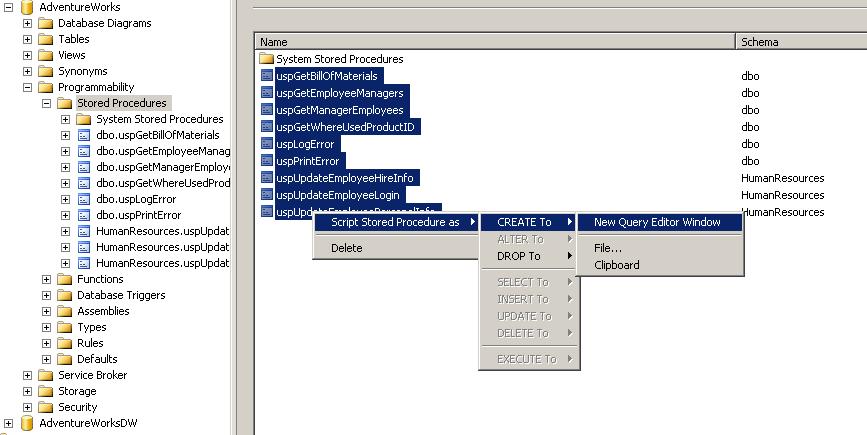
Thursday, April 20, 2006
SQL Server 2005 Service Pack 1 Download Link
Yesterday I reported that Service Pack 1 was available for download but I never posted the link so here it is with a 24 hour delay
http://www.microsoft.com/downloads/details.aspx?displaylang=en&FamilyID=cb6c71ea-d649-47ff-9176-e7cac58fd4bc
http://www.microsoft.com/downloads/details.aspx?displaylang=en&FamilyID=cb6c71ea-d649-47ff-9176-e7cac58fd4bc
Wednesday, April 19, 2006
Microsoft Releases SQL Server 2005 Service Pack 1
Microsoft Corp. today announced the availability of Microsoft® SQL Server™ 2005 Service Pack 1 (SP1), the product’s first major milestone since the launch of SQL Server 2005 only a few months ago. The release follows the remarkable reception, momentum and feedback offered by customers and partners in 92 countries. This has informed and accelerated Microsoft’s multiyear vision of Your Data, Any Place, Any Time. Microsoft SQL Server 2005 SP1 includes production-ready Database Mirroring functionality and the new SQL Server Management Studio Express, along with additional updates to SQL Server 2005 Express Edition targeted at users such as independent software vendors (ISVs) wanting to take advantage of greater functionality.
SP1 delivers production-ready Database Mirroring functionality for continuous availability. This complements the existing Always On Technologies in SQL Server 2005 such as failover clustering, database snapshots, snapshot isolation and log shipping. Since launch, Database Mirroring has been extensively tested by Microsoft and its thriving customer community to help ensure that it provides the high availability necessary for the largest customer deployments. Today more than 20 SQL Server customers have deployed Database Mirroring into production
SP1 extends business insight to smaller-scale customers and ISVs using the free SQL Server 2005 Express Edition, which includes SQL Server Reporting Services (SSRS) functionality, Full Text Search and the newly released SQL Server Management Studio Express. This optional set of capabilities is already receiving positive feedback from Microsoft’s ISV partners
SP1 also advances dynamic applications with the new SQL Server Management Studio Express, a simplified graphical management environment for SQL Server Express Edition. This tool builds on Microsoft’s commitment to extending the breadth of the SQL Server family to support all the data storage needs of Microsoft’s customers. It also complements the recently announced SQL Server Everywhere Edition, a lightweight and rich subset of capabilities found in other SQL Server editions, targeted for application embedded storage on clients. SQL Server Everywhere Edition is targeted to be available as a Community Technology Preview (CTP) this summer and released by year end.
For end-to-end business insight, SP1 extends SSRS to support enterprise reporting on SAP NetWeaver Business Intelligence with two new components in SP1: a Microsoft .NET Data provider for SAP NetWeaver Business Intelligence and a new MDX Query Designer. This new functionality extends the benefits of enterprise reporting with SQL Server by enabling SAP customers to easily create and manage reports on information inside any SAP BW data warehouse
SP1 delivers production-ready Database Mirroring functionality for continuous availability. This complements the existing Always On Technologies in SQL Server 2005 such as failover clustering, database snapshots, snapshot isolation and log shipping. Since launch, Database Mirroring has been extensively tested by Microsoft and its thriving customer community to help ensure that it provides the high availability necessary for the largest customer deployments. Today more than 20 SQL Server customers have deployed Database Mirroring into production
SP1 extends business insight to smaller-scale customers and ISVs using the free SQL Server 2005 Express Edition, which includes SQL Server Reporting Services (SSRS) functionality, Full Text Search and the newly released SQL Server Management Studio Express. This optional set of capabilities is already receiving positive feedback from Microsoft’s ISV partners
SP1 also advances dynamic applications with the new SQL Server Management Studio Express, a simplified graphical management environment for SQL Server Express Edition. This tool builds on Microsoft’s commitment to extending the breadth of the SQL Server family to support all the data storage needs of Microsoft’s customers. It also complements the recently announced SQL Server Everywhere Edition, a lightweight and rich subset of capabilities found in other SQL Server editions, targeted for application embedded storage on clients. SQL Server Everywhere Edition is targeted to be available as a Community Technology Preview (CTP) this summer and released by year end.
For end-to-end business insight, SP1 extends SSRS to support enterprise reporting on SAP NetWeaver Business Intelligence with two new components in SP1: a Microsoft .NET Data provider for SAP NetWeaver Business Intelligence and a new MDX Query Designer. This new functionality extends the benefits of enterprise reporting with SQL Server by enabling SAP customers to easily create and manage reports on information inside any SAP BW data warehouse
Inside Microsoft SQL Server 2005: T-SQL Querying
 How did I miss this? SQL Server MVP Itzik Ben-Gan has published his latest book: Inside Microsoft SQL Server 2005: T-SQL Querying. For all of you who read SQL Server magazine you probably know Itzik from his great SQL tips and puzzles articles.
How did I miss this? SQL Server MVP Itzik Ben-Gan has published his latest book: Inside Microsoft SQL Server 2005: T-SQL Querying. For all of you who read SQL Server magazine you probably know Itzik from his great SQL tips and puzzles articles.Take a detailed look at the internal architecture of T-SQL—and unveil the power of set-based querying—with comprehensive reference and advice from the experts. Database developers and administrators get best practices, sample databases, and code to master the intricacies of the programming language—solving complex problems with real-world solutions.
Discover how to:
•Understand logical and physical query processing
•Apply a methodology to optimize query tuning
•Solve relational division problems
•Use CTEs and ranking functions to simplify and optimize solutions
•Aggregate data with various techniques, including tiebreakers, pivoting, histograms, and grouping factors
•Use the TOP option in a query to modify data
•Query specialized data structures with recursive logic, materialized path, or nested sets solutions
•PLUS—Improve your logic and get to the heart of querying problems with logic puzzles
The book is 640 printed pages, below is the table of contents
Chapter 01 - Logical Query Processing
Chapter 02 - Physical Query Processing
Chapter 03 - Query Tuning
Chapter 04 - Subqueries, Table Expressions and Ranking Functions
Chapter 05 - Joins and Set Operations
Chapter 06 - Aggregating and Pivoting Data
Chapter 07 - TOP and APPLY
Chapter 08 - Data Modification
Chapter 09 - Graphs, Trees, Hierarchies and Recursive Queries
Appendix A - Logic Puzzles
I could not find a sample chapter yet but as soon one is available I will create a link to it
If you are intereseted in purchasing this book the Amazon link is here
Tuesday, April 18, 2006
Use PARSENAME, CHARINDEX, PATINDEX or SUBSTRING To Grab Values Up To A Certain Character
This is a question that came up yesterday in the Getting started with SQL Server MSDN forum (http://forums.microsoft.com/MSDN/ShowPost.aspx?PostID=353250&SiteID=1)
A person wanted to use a MID function in SQL Server, There is no MID function in SQL Server but there are at least 4 ways to implement what the person tried to accomplish
Basically if the data looked like this
aaa-bbbbb
ppppp-bbbbb
zzzz-xxxxx
Then we need to grab everything up until the minus sign
So let's get started
CREATE TABLE #Test (
SomeField VARCHAR(49))
INSERT INTO #Test
VALUES ('aaa-bbbbb')
INSERT INTO #Test
VALUES ('ppppp-bbbbb')
INSERT INTO #Test
VALUES ('zzzz-xxxxx')
--using PARSENAME
SELECT PARSENAME(REPLACE(SomeField,'-','.'),2)
FROM #Test
--using LEFT and CHARINDEX
SELECT LEFT(SomeField,CHARINDEX('-',SomeField) - 1)
FROM #Test
--using LEFT and PATINDEX
SELECT LEFT(SomeField,PATINDEX('%-%',SomeField) - 1)
FROM #Test
--using CASE SUBSTRING and LEFT
SELECT CASE SUBSTRING(SomeField,4,1)
WHEN '-' THEN LEFT(SomeField,3)
ELSE LEFT(SomeField,4)
END
FROM #Test
--clean up
DROP TABLE #Test
A person wanted to use a MID function in SQL Server, There is no MID function in SQL Server but there are at least 4 ways to implement what the person tried to accomplish
Basically if the data looked like this
aaa-bbbbb
ppppp-bbbbb
zzzz-xxxxx
Then we need to grab everything up until the minus sign
So let's get started
CREATE TABLE #Test (
SomeField VARCHAR(49))
INSERT INTO #Test
VALUES ('aaa-bbbbb')
INSERT INTO #Test
VALUES ('ppppp-bbbbb')
INSERT INTO #Test
VALUES ('zzzz-xxxxx')
--using PARSENAME
SELECT PARSENAME(REPLACE(SomeField,'-','.'),2)
FROM #Test
--using LEFT and CHARINDEX
SELECT LEFT(SomeField,CHARINDEX('-',SomeField) - 1)
FROM #Test
--using LEFT and PATINDEX
SELECT LEFT(SomeField,PATINDEX('%-%',SomeField) - 1)
FROM #Test
--using CASE SUBSTRING and LEFT
SELECT CASE SUBSTRING(SomeField,4,1)
WHEN '-' THEN LEFT(SomeField,3)
ELSE LEFT(SomeField,4)
END
FROM #Test
--clean up
DROP TABLE #Test
Monday, April 17, 2006
Grant Execute/SELECT Permissions For All User Defined Functions To A User
You want to add a new user with read and write access and also the ability to execute all user defined functions but you don't want to make the user a db_owner. The code below will do a GRANT EXECUTE/SELECT for all the user defined functions in the DB If the user defined function is a table-valued function then you need to grant select permissions otherwise you need to grant execute permissions
Right now this code prints the GRANT EXECUTE/SELECT statements, change the PRINT to EXEC if you want it to be done automatically
--Grab all the functions for the current DB
SELECT IDENTITY(INT,1,1) AS ID,
SPECIFIC_NAME,DATA_TYPE
INTO #FunctionList
FROM INFORMATION_SCHEMA.ROUTINES --Only Procs
WHERE OBJECTPROPERTY(OBJECT_ID(SPECIFIC_NAME),'IsMSShipped') =0
AND ROUTINE_TYPE='FUNCTION'
ORDER BY SPECIFIC_NAME
DECLARE
@Loopid INT,
@MaxId INT,
@UserName VARCHAR(50)
--This is the user that will get the execute/select permissions
SELECT @UserName = 'SomeUser'
--Grab start and end values for the loop
SELECT @Loopid = 1,
@MaxId = MAX(ID)
FROM #FunctionList
DECLARE
@SQL VARCHAR(500),
@ProcName VARCHAR(400) ,
@Permission VARCHAR(20),
@DataType VARCHAR(20)
--This is where the loop starts
WHILE @Loopid <= @MaxId BEGIN
--grab the function name and type
SELECT @ProcName = SPECIFIC_NAME, @DataType =DATA_TYPE
FROM #FunctionList
WHERE ID = @Loopid
--Find out if it's a table-valued function
IF @DataType ='TABLE'
SELECT @Permission ='SELECT'
ELSE
SELECT @Permission ='EXECUTE'
Right now this code prints the GRANT EXECUTE/SELECT statements, change the PRINT to EXEC if you want it to be done automatically
--Grab all the functions for the current DB
SELECT IDENTITY(INT,1,1) AS ID,
SPECIFIC_NAME,DATA_TYPE
INTO #FunctionList
FROM INFORMATION_SCHEMA.ROUTINES --Only Procs
WHERE OBJECTPROPERTY(OBJECT_ID(SPECIFIC_NAME),'IsMSShipped') =0
AND ROUTINE_TYPE='FUNCTION'
ORDER BY SPECIFIC_NAME
DECLARE
@Loopid INT,
@MaxId INT,
@UserName VARCHAR(50)
--This is the user that will get the execute/select permissions
SELECT @UserName = 'SomeUser'
--Grab start and end values for the loop
SELECT @Loopid = 1,
@MaxId = MAX(ID)
FROM #FunctionList
DECLARE
@SQL VARCHAR(500),
@ProcName VARCHAR(400) ,
@Permission VARCHAR(20),
@DataType VARCHAR(20)
--This is where the loop starts
WHILE @Loopid <= @MaxId BEGIN
--grab the function name and type
SELECT @ProcName = SPECIFIC_NAME, @DataType =DATA_TYPE
FROM #FunctionList
WHERE ID = @Loopid
--Find out if it's a table-valued function
IF @DataType ='TABLE'
SELECT @Permission ='SELECT'
ELSE
SELECT @Permission ='EXECUTE'
--construct the statement
SELECT @SQL = 'GRANT ' + @Permission +' ON [' + @ProcName + '] TO ' + @UserName
PRINT (@SQL) --change PRINT to EXECUTE if you want it to run automatically
--increment counter
SET @Loopid = @Loopid + 1
END
--clean up
DROP TABLE #FunctionList
Thursday, April 13, 2006
Grant Execute Permissions For All Stored Procedures To A User
You want to add a new user with read and write access and also the ability to execute all stored procedures but you don't want to make the user a db_owner.
The code below will do a GRANT EXECUTE for all the procedures in the DB
This line will skip those dt_ procedures that are in every database
WHERE OBJECTPROPERTY(OBJECT_ID(SPECIFIC_NAME),'IsMSShipped') =0
Right now this code prints the GRANT EXECUTE statements, change the PRINT to EXEC if you want it to be done automatically
--Grab all the procedures for the current DB
SELECT IDENTITY(INT,1,1) AS ID,
SPECIFIC_NAME
INTO #Procedurelist
FROM INFORMATION_SCHEMA.ROUTINES --Only Procs
WHERE OBJECTPROPERTY(OBJECT_ID(SPECIFIC_NAME),'IsMSShipped') =0
AND ROUTINE_TYPE='PROCEDURE'
ORDER BY SPECIFIC_NAME
DECLARE
@Loopid INT,
@MaxId INT,
@UserName VARCHAR(50)
--This is the user that will get the execute permissions
SELECT @UserName = 'SomeUser'
--Grab start and end values for the loop
SELECT @Loopid = 1,
@MaxId = MAX(ID)
FROM #Procedurelist
DECLARE
@SQL VARCHAR(500),
@ProcName VARCHAR(400)
--This is where the loop starts
WHILE @Loopid <= @MaxId BEGIN
--grab the procedure name
SELECT @ProcName = SPECIFIC_NAME
FROM #Procedurelist
WHERE ID = @Loopid
--construct the statement
SELECT @SQL = 'GRANT EXECUTE ON ' + @ProcName + ' TO ' + @UserName
PRINT (@SQL) --change PRINT to EXECUTE if you want it to run automatically
--increment counter
SET @Loopid = @Loopid + 1
END
--clean up
DROP TABLE #Procedurelist
The code below will do a GRANT EXECUTE for all the procedures in the DB
This line will skip those dt_ procedures that are in every database
WHERE OBJECTPROPERTY(OBJECT_ID(SPECIFIC_NAME),'IsMSShipped') =0
Right now this code prints the GRANT EXECUTE statements, change the PRINT to EXEC if you want it to be done automatically
--Grab all the procedures for the current DB
SELECT IDENTITY(INT,1,1) AS ID,
SPECIFIC_NAME
INTO #Procedurelist
FROM INFORMATION_SCHEMA.ROUTINES --Only Procs
WHERE OBJECTPROPERTY(OBJECT_ID(SPECIFIC_NAME),'IsMSShipped') =0
AND ROUTINE_TYPE='PROCEDURE'
ORDER BY SPECIFIC_NAME
DECLARE
@Loopid INT,
@MaxId INT,
@UserName VARCHAR(50)
--This is the user that will get the execute permissions
SELECT @UserName = 'SomeUser'
--Grab start and end values for the loop
SELECT @Loopid = 1,
@MaxId = MAX(ID)
FROM #Procedurelist
DECLARE
@SQL VARCHAR(500),
@ProcName VARCHAR(400)
--This is where the loop starts
WHILE @Loopid <= @MaxId BEGIN
--grab the procedure name
SELECT @ProcName = SPECIFIC_NAME
FROM #Procedurelist
WHERE ID = @Loopid
--construct the statement
SELECT @SQL = 'GRANT EXECUTE ON ' + @ProcName + ' TO ' + @UserName
PRINT (@SQL) --change PRINT to EXECUTE if you want it to run automatically
--increment counter
SET @Loopid = @Loopid + 1
END
--clean up
DROP TABLE #Procedurelist
Wednesday, April 12, 2006
Use OBJECT_DEFINITION To Track Procedure Changes
Not everyone uses Visual Source Safe, CVS or Subversion to keep track of proc changes/deletions and/or additions
Of course you could use Red-Gate SQL Compare (I do) But let's say you don't have any of these tools and are using SQL Server 2005, what else can you do?
In SQL Server 2000 you can use
select ROUTINE_DEFINITION,SPECIFIC_NAME FROM INFORMATION_SCHEMA.ROUTINES to get the body of the stored procedure, the caveat is that this will only return 4000 characters.
Another way is to use the sp_helptext procedure
In SQL server 2005 this is much easier. There is a new function in town: OBJECT_DEFINITION()
OBJECT_DEFINITION() does return the whole body of a stored procedure
Below is some code (very simple) that will give you an idea of how you could use OBJECT_DEFINITION() to keep track of changes
You will have to setup a job that runs once a day and stores the definition of all the procedures in a table
Then you can do a self join on that table to find added, deleted and changed procedures
You can run the code below in 1 shot if you want
USE master
GO
--Let's Create a New Database
CREATE DATABASE TestProcCode
GO
USE TestProcCode
GO
--proc0
CREATE PROC proc0
AS
SELECT CURRENT_TIMESTAMP
GO
--proc1
CREATE PROC proc1
AS
SELECT GETDATE()
GO
--proc2
CREATE PROC proc2
AS
SELECT HOST_NAME()
GO
--create the proc changes table, bad name I know
CREATE TABLE ProcChanges (ID INT IDENTITY,RunDate DATETIME,ProcName VARCHAR(100),ProcCode VARCHAR(MAX))
GO
--insert all the procs that exist now
INSERT INTO ProcChanges
SELECT '20060410',SPECIFIC_NAME,OBJECT_DEFINITION( OBJECT_ID(SPECIFIC_NAME))
FROM INFORMATION_SCHEMA.ROUTINES
GO
--Let's change proc2
ALTER PROC proc2
AS
SELECT HOST_ID()
GO
--proc 3 is new
CREATE PROC proc3
AS
SELECT SUSER_SNAME()
GO
--proc 1 is deleted
DROP PROCEDURE proc1
GO
--insert all the procs that exist now
INSERT INTO ProcChanges
SELECT '20060411',SPECIFIC_NAME,OBJECT_DEFINITION( OBJECT_ID(SPECIFIC_NAME))
FROM INFORMATION_SCHEMA.ROUTINES
GO
--grab all deleted procs
SELECT 'Deleted',p1.*
FROM ProcChanges p1
LEFT OUTER JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
AND p2.RunDAte ='20060411'
WHERE p1.RunDAte ='20060410'
AND p2.ID IS NULL
--grab all added procs
SELECT 'Added',p1.*
FROM ProcChanges p1
LEFT OUTER JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
AND p2.RunDAte ='20060410'
WHERE p1.RunDAte ='20060411'
AND p2.ID IS NULL
--grab all changed procs
SELECT 'Changed',p1.*
FROM ProcChanges p1
JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
WHERE p1.RunDAte ='20060410'
AND p2.RunDAte ='20060411'
AND p1.ProcCode <> p2.ProcCode
--grab all procs that didn't change
SELECT 'Not Changed',p1.*
FROM ProcChanges p1
JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
WHERE p1.RunDAte ='20060410'
AND p2.RunDAte ='20060411'
AND p1.ProcCode = p2.ProcCode
USE MASTER
GO
--let's clean up this mess ;-)
DROP DATABASE TestProcCode
GO
What I have shown is very simple, you can expand on this and check for date ranges and improve on this a lot if you need to
Of course you could use Red-Gate SQL Compare (I do) But let's say you don't have any of these tools and are using SQL Server 2005, what else can you do?
In SQL Server 2000 you can use
select ROUTINE_DEFINITION,SPECIFIC_NAME FROM INFORMATION_SCHEMA.ROUTINES to get the body of the stored procedure, the caveat is that this will only return 4000 characters.
Another way is to use the sp_helptext procedure
In SQL server 2005 this is much easier. There is a new function in town: OBJECT_DEFINITION()
OBJECT_DEFINITION() does return the whole body of a stored procedure
Below is some code (very simple) that will give you an idea of how you could use OBJECT_DEFINITION() to keep track of changes
You will have to setup a job that runs once a day and stores the definition of all the procedures in a table
Then you can do a self join on that table to find added, deleted and changed procedures
You can run the code below in 1 shot if you want
USE master
GO
--Let's Create a New Database
CREATE DATABASE TestProcCode
GO
USE TestProcCode
GO
--proc0
CREATE PROC proc0
AS
SELECT CURRENT_TIMESTAMP
GO
--proc1
CREATE PROC proc1
AS
SELECT GETDATE()
GO
--proc2
CREATE PROC proc2
AS
SELECT HOST_NAME()
GO
--create the proc changes table, bad name I know
CREATE TABLE ProcChanges (ID INT IDENTITY,RunDate DATETIME,ProcName VARCHAR(100),ProcCode VARCHAR(MAX))
GO
--insert all the procs that exist now
INSERT INTO ProcChanges
SELECT '20060410',SPECIFIC_NAME,OBJECT_DEFINITION( OBJECT_ID(SPECIFIC_NAME))
FROM INFORMATION_SCHEMA.ROUTINES
GO
--Let's change proc2
ALTER PROC proc2
AS
SELECT HOST_ID()
GO
--proc 3 is new
CREATE PROC proc3
AS
SELECT SUSER_SNAME()
GO
--proc 1 is deleted
DROP PROCEDURE proc1
GO
--insert all the procs that exist now
INSERT INTO ProcChanges
SELECT '20060411',SPECIFIC_NAME,OBJECT_DEFINITION( OBJECT_ID(SPECIFIC_NAME))
FROM INFORMATION_SCHEMA.ROUTINES
GO
--grab all deleted procs
SELECT 'Deleted',p1.*
FROM ProcChanges p1
LEFT OUTER JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
AND p2.RunDAte ='20060411'
WHERE p1.RunDAte ='20060410'
AND p2.ID IS NULL
--grab all added procs
SELECT 'Added',p1.*
FROM ProcChanges p1
LEFT OUTER JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
AND p2.RunDAte ='20060410'
WHERE p1.RunDAte ='20060411'
AND p2.ID IS NULL
--grab all changed procs
SELECT 'Changed',p1.*
FROM ProcChanges p1
JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
WHERE p1.RunDAte ='20060410'
AND p2.RunDAte ='20060411'
AND p1.ProcCode <> p2.ProcCode
--grab all procs that didn't change
SELECT 'Not Changed',p1.*
FROM ProcChanges p1
JOIN ProcChanges p2 ON p1.ProcName =p2.ProcName
WHERE p1.RunDAte ='20060410'
AND p2.RunDAte ='20060411'
AND p1.ProcCode = p2.ProcCode
USE MASTER
GO
--let's clean up this mess ;-)
DROP DATABASE TestProcCode
GO
What I have shown is very simple, you can expand on this and check for date ranges and improve on this a lot if you need to
Monday, April 10, 2006
NULL Is Not 'NULL'
Today someone posted a question on the Tek-Tips Forums web site
The queston was how not to insert rows with a NULL value in a certain column
The answer is of course INSERT INTO Table2 SELECT * FROM table WHERE column IS NOT NULL
This person replied that rows where the column is null are still being inserted
I turned out that there was data that had NULL character values 'NULL'
When you run SELECT NULL,'NULL' in Query Analyzer or SQL Server Managment Studio this looks identical so it's very easy to think that there is something else going on
Run the code below in Query Analyzer to understand what I mean
CREATE TABLE #test (
SomeField VARCHAR(50))
INSERT INTO #test
VALUES (NULL)
INSERT INTO #test
VALUES ('NULL')
SELECT *
FROM #test
SELECT *
FROM #test
WHERE SomeField IS NOT NULL
SELECT *
FROM #test
WHERE SomeField = 'NULL'
DROP TABLE #test
The queston was how not to insert rows with a NULL value in a certain column
The answer is of course INSERT INTO Table2 SELECT * FROM table WHERE column IS NOT NULL
This person replied that rows where the column is null are still being inserted
I turned out that there was data that had NULL character values 'NULL'
When you run SELECT NULL,'NULL' in Query Analyzer or SQL Server Managment Studio this looks identical so it's very easy to think that there is something else going on
Run the code below in Query Analyzer to understand what I mean
CREATE TABLE #test (
SomeField VARCHAR(50))
INSERT INTO #test
VALUES (NULL)
INSERT INTO #test
VALUES ('NULL')
SELECT *
FROM #test
SELECT *
FROM #test
WHERE SomeField IS NOT NULL
SELECT *
FROM #test
WHERE SomeField = 'NULL'
DROP TABLE #test
Friday, April 07, 2006
SQL Server Everywhere Edition <> Sybase SQL Anywhere
Paul Flessner Senior Vice President of Microsoft Corporation has posted a SQL Server 2005 update here
Am I the only one who thinks that the name "SQL Server Everywhere Edition" is very close to "Sybase SQL Anywhere"?
I can see the jokes already "Not only does SQL server have the same codebase (not true) the name is also ripped off"
Anyway these are the 4 key themes that Paul Flessner mentioned
Continuous Availability and Automation
Beyond Relational
Dynamic Applications
End-To-End Insight
This is what Paul has to say about SQL Server Everywhere Edition "This new offering for storage on clients of all types will provide a lightweight, compact, but rich subset of the capabilities found in other SQL Server editions. Beyond having rich local data management capabilities, SQL Server Everywhere Edition will also include support for seamlessly synchronizing with other SQL Server editions and provides features that promote building rich client applications that operate effectively in today’s increasingly “occasionally connected” environment. SQL Server Everywhere Edition also shares a common programming model with the other SQL Server editions, enabling developers to transfer skills and knowledge quickly and easily. We expect to ship the first CTP of SQL Server Everywhere Edition this summer, with the goal of final release before the end of this calendar year."
Am I the only one who thinks that the name "SQL Server Everywhere Edition" is very close to "Sybase SQL Anywhere"?
I can see the jokes already "Not only does SQL server have the same codebase (not true) the name is also ripped off"
Anyway these are the 4 key themes that Paul Flessner mentioned
Continuous Availability and Automation
Beyond Relational
Dynamic Applications
End-To-End Insight
This is what Paul has to say about SQL Server Everywhere Edition "This new offering for storage on clients of all types will provide a lightweight, compact, but rich subset of the capabilities found in other SQL Server editions. Beyond having rich local data management capabilities, SQL Server Everywhere Edition will also include support for seamlessly synchronizing with other SQL Server editions and provides features that promote building rich client applications that operate effectively in today’s increasingly “occasionally connected” environment. SQL Server Everywhere Edition also shares a common programming model with the other SQL Server editions, enabling developers to transfer skills and knowledge quickly and easily. We expect to ship the first CTP of SQL Server Everywhere Edition this summer, with the goal of final release before the end of this calendar year."
Wednesday, April 05, 2006
Left Join
As promised here is a left join blog post. What is a left (outer) join? This is what Books On Line has as the left join description “The Left Outer Join logical operator returns each row that satisfies the join of the first (top) input with the second (bottom) input. It also returns any rows from the first input that had no matching rows in the second input. The nonmatching rows in the second input are returned as null values. If no join predicate exists in the Argument column, each row is a matching row.”
So let’s see how that works
CREATE TABLE #Customer
(CustomerID INT ,
LastName VARCHAR(100),
FirstName VARCHAR(100))
CREATE TABLE #Order
(OrderID INT identity ,
Amount DECIMAL(12,3),
CustomerID INT)
INSERT INTO #Customer VALUES (1,'Gates','Bill')
INSERT INTO #Customer VALUES (2,'Woz','Steve')
INSERT INTO #Customer VALUES (3,'Ellison','Larry')
INSERT INTO #Order VALUES (12.99,1)
INSERT INTO #Order VALUES (13.45,1)
INSERT INTO #Order VALUES (56.45,3)
--Regular Join, CustomerID 2 is not returned
SELECT c.*,o.*
FROM #Customer c
JOIN #Order o ON c.CustomerID =o.CustomerID
--Left Join, CustomerID 2 is returned
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
--Right Join, CustomerID 2 is returned
SELECT c.*,o.*
FROM #Order o
RIGHT JOIN #Customer c ON c.CustomerID =o.CustomerID
--Return all the people without an order
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
WHERE o.CustomerID IS NULL
--Left Join, CustomerID 2 is not returned because the condition is in the WHERE clause
--The WHERE clause is applied to the #Order table instead of the #Customer table
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
WHERE o.CustomerID < 3
--Left Join, CustomerID 2 is returned (as well as 3) because the condition is in the AND clause
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
AND o.CustomerID < color="#009900">
--The 'correct' way, applying the WHERE condition to the #Customer table
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
WHERE c.CustomerID < 3
DROP TABLE #Order,#Customer
So let’s see how that works
CREATE TABLE #Customer
(CustomerID INT ,
LastName VARCHAR(100),
FirstName VARCHAR(100))
CREATE TABLE #Order
(OrderID INT identity ,
Amount DECIMAL(12,3),
CustomerID INT)
INSERT INTO #Customer VALUES (1,'Gates','Bill')
INSERT INTO #Customer VALUES (2,'Woz','Steve')
INSERT INTO #Customer VALUES (3,'Ellison','Larry')
INSERT INTO #Order VALUES (12.99,1)
INSERT INTO #Order VALUES (13.45,1)
INSERT INTO #Order VALUES (56.45,3)
--Regular Join, CustomerID 2 is not returned
SELECT c.*,o.*
FROM #Customer c
JOIN #Order o ON c.CustomerID =o.CustomerID
--Left Join, CustomerID 2 is returned
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
--Right Join, CustomerID 2 is returned
SELECT c.*,o.*
FROM #Order o
RIGHT JOIN #Customer c ON c.CustomerID =o.CustomerID
--Return all the people without an order
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
WHERE o.CustomerID IS NULL
--Left Join, CustomerID 2 is not returned because the condition is in the WHERE clause
--The WHERE clause is applied to the #Order table instead of the #Customer table
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
WHERE o.CustomerID < 3
--Left Join, CustomerID 2 is returned (as well as 3) because the condition is in the AND clause
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
AND o.CustomerID < color="#009900">
--The 'correct' way, applying the WHERE condition to the #Customer table
SELECT c.*,o.*
FROM #Customer c
LEFT JOIN #Order o ON c.CustomerID =o.CustomerID
WHERE c.CustomerID < 3
DROP TABLE #Order,#Customer
Tuesday, April 04, 2006
Top SQL Server Google Searches For March 2006
These are the top SQL Searches on this site for the month of March. I have left out searches that have nothing to do with SQL Server or programming. Here are the results...
ToBase64String sql procedure
type of database backup
how to view the picture files for a particular date using sql command
Crystal reports
SQL group right
SQL SERVER create table select
SQL MID
i need to know about money laundry and bluk currency smuggling
AMD SQL Server Performance
sql monitor
convert mysql mssql
trigger
left join SQL Server
left join
It's always interesting to see what people are searching for, I left the money laundry one in this list because I thought it was kind of amusing
I always like to look at this list so that I know what people are interested in and I can write a little thing about it
So tomorrow I will cover LEFT JOIN
ToBase64String sql procedure
type of database backup
how to view the picture files for a particular date using sql command
Crystal reports
SQL group right
SQL SERVER create table select
SQL MID
i need to know about money laundry and bluk currency smuggling
AMD SQL Server Performance
sql monitor
convert mysql mssql
trigger
left join SQL Server
left join
It's always interesting to see what people are searching for, I left the money laundry one in this list because I thought it was kind of amusing
I always like to look at this list so that I know what people are interested in and I can write a little thing about it
So tomorrow I will cover LEFT JOIN
Top 5 SQL Server Posts for March 2006
Below are the top 5 posts according to Google Analytics for the month of March
Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
SQL Server 2005 Free E-Learning
SQL Query Optimizations
Feature Pack for Microsoft SQL Server 2005
Find all Primary and Foreign Keys In A Database
Login failed for user 'sa'. Reason: Not associated with a trusted SQL Server connection. SQL 2005
SQL Server 2005 Free E-Learning
SQL Query Optimizations
Feature Pack for Microsoft SQL Server 2005
Find all Primary and Foreign Keys In A Database
SQL Server 2005 Distilled Book Published
 Addison Wesley Professional has published their latest SQL Server 2005 book "SQL Server 2005 Distilled"
Addison Wesley Professional has published their latest SQL Server 2005 book "SQL Server 2005 Distilled"Book Description
Need to get your arms around Microsoft SQL Server 2005 fast, without getting buried in the details? Need to make fundamental decisions about deploying, using, or administering Microsoft’s latest enterprise database?
Need to understand what’s new in SQL Server 2005, and how it fits with your existing IT and business infrastructure? SQL Server 2005 Distilled delivers the answers you need–quickly, clearly, and objectively.
Former SQL Server team member Eric L. Brown offers realistic insight into every significant aspect of SQL Server 2005: its new features, architecture, administrative tools, security model, data management capabilities, development environment, and much more. Brown draws on his extensive experience consulting with enterprise users, outlining realistic usage scenarios that leverage SQL Server 2005’s strengths and minimize its limitations. Coverage includes
Architectural overview: how SQL Server 2005’s features work together and what it means to you
Security management, policies, and permissions: gaining tighter control over your data
SQL Server Management Studio: Microsoft’s new, unified tool suite for authoring, management, and operations
Availability enhancements: online restoration, improved replication, shorter maintenance/recovery windows, and more
Scalability improvements, including a practical explanation of SQL Server 2005’s complex table partitioning feature
Data access enhancements, from ADO.NET 2.0 to XML
SQL Server 2005’s built-in .NET CLR: how to use it, when to use it, and when to stay with T-SQL
Business Intelligence Development Studio: leveraging major improvements in reporting and analytics
Visual Studio integration: improving efficiency throughout the coding and debugging process
Simple code examples demonstrating SQL Server 2005’s most significant new features
Table of Contents
Preface xiii
Acknowledgments xv
About the Author xvii
Chapter 1: Introduction to SQL Server 2005 1
Chapter 2: What Everyone Should Know About Security 41
Chapter 3: Enterprise Data Management 83
Chapter 4: Features for Database Development 145
Chapter 5: Overview of Business Intelligence 197
Chapter 6: The Code Chapter 245
Appendix A: SQL Server 2005 System Information 285
Appendix B: System Tables and View in SQL Server 2005 291
Appendix C: SQL Server Built-In Functions 295
Index 297
The Amazon link is here
Tuesday, March 28, 2006
Use sp_executesql Or EXEC To Get The Count For Dynamic Table Names
You need the record count for a table but this table could change every day or change based on which user executes the stored procedure
There is no point in creating dozens of stored procedures, all this can be done by using exec (sql) or sp_executesql
Of course sp_executesql is much better and if you run the statements below you will also see that it's execution plan is only 29.04 percent relative to the batch
So let's get started with sp_executesql
USE pubs
GO
--sp_executesql
DECLARE @chvTableName VARCHAR(100),
@intTableCount INT,
@chvSQL NVARCHAR(100)
SELECT @chvTableName = 'Authors'
SELECT @chvSQL = N'SELECT @intTableCount = COUNT(*) FROM ' + @chvTableName
EXEC sp_executesql @chvSQL, N'@intTableCount INT OUTPUT', @intTableCount OUTPUT
SELECT @intTableCount
GO
--EXEC (SQL)
DECLARE @chvTableName VARCHAR(100),
@intTableCount INT,
@chvSQL NVARCHAR(100)
CREATE TABLE #temp (Totalcount INT)
SELECT @chvTableName = 'Authors'
SELECT @chvSQL = 'Insert into #temp Select Count(*) from ' + @chvTableName
EXEC( @chvSQL)
SELECT @intTableCount = Totalcount from #temp
SELECT @intTableCount
DROP TABLE #temp
First Hit CTRL + K (this will show the execution plan) , then highlight the complete code, hit F5 and look at the Execution Plan tab
As you can see sp_executesql is more than twice as efficient as exec (SQL)
There is no point in creating dozens of stored procedures, all this can be done by using exec (sql) or sp_executesql
Of course sp_executesql is much better and if you run the statements below you will also see that it's execution plan is only 29.04 percent relative to the batch
So let's get started with sp_executesql
USE pubs
GO
--sp_executesql
DECLARE @chvTableName VARCHAR(100),
@intTableCount INT,
@chvSQL NVARCHAR(100)
SELECT @chvTableName = 'Authors'
SELECT @chvSQL = N'SELECT @intTableCount = COUNT(*) FROM ' + @chvTableName
EXEC sp_executesql @chvSQL, N'@intTableCount INT OUTPUT', @intTableCount OUTPUT
SELECT @intTableCount
GO
--EXEC (SQL)
DECLARE @chvTableName VARCHAR(100),
@intTableCount INT,
@chvSQL NVARCHAR(100)
CREATE TABLE #temp (Totalcount INT)
SELECT @chvTableName = 'Authors'
SELECT @chvSQL = 'Insert into #temp Select Count(*) from ' + @chvTableName
EXEC( @chvSQL)
SELECT @intTableCount = Totalcount from #temp
SELECT @intTableCount
DROP TABLE #temp
First Hit CTRL + K (this will show the execution plan) , then highlight the complete code, hit F5 and look at the Execution Plan tab
As you can see sp_executesql is more than twice as efficient as exec (SQL)
Monday, March 27, 2006
Use DATEADD And DATEDIFF To Get The First And Last Day Of The Month
Here are a couple different ways to get the first day of the current month, the first day of next month and finally the last day of the current month
Nothing special really, it is just a matter of applying datediff and dateadd
This was a question that I answered in the Transact-SQL MSDN Forum
The first day of the current month
SELECT DATEADD(mm, DATEDIFF(mm, 0, GETDATE())+0, 0)
SELECT CONVERT(DATETIME,(CONVERT(VARCHAR(6),GETDATE(),112) + '01'))
The first day of next month
SELECT DATEADD(mm, DATEDIFF(mm, 0, GETDATE())+1, 0)
SELECT DATEADD(mm,1,CONVERT(DATETIME,(CONVERT(VARCHAR(6),GETDATE(),112) + '01')))
The last day of the current month
SELECT DATEADD(d,-1,DATEADD(mm, DATEDIFF(mm, 0, GETDATE())+1, 0))
SELECT DATEADD(d,-1,DATEADD(mm,1,CONVERT(DATETIME,(CONVERT(VARCHAR(6),GETDATE(),112) + '01'))))
Nothing special really, it is just a matter of applying datediff and dateadd
This was a question that I answered in the Transact-SQL MSDN Forum
The first day of the current month
SELECT DATEADD(mm, DATEDIFF(mm, 0, GETDATE())+0, 0)
SELECT CONVERT(DATETIME,(CONVERT(VARCHAR(6),GETDATE(),112) + '01'))
The first day of next month
SELECT DATEADD(mm, DATEDIFF(mm, 0, GETDATE())+1, 0)
SELECT DATEADD(mm,1,CONVERT(DATETIME,(CONVERT(VARCHAR(6),GETDATE(),112) + '01')))
The last day of the current month
SELECT DATEADD(d,-1,DATEADD(mm, DATEDIFF(mm, 0, GETDATE())+1, 0))
SELECT DATEADD(d,-1,DATEADD(mm,1,CONVERT(DATETIME,(CONVERT(VARCHAR(6),GETDATE(),112) + '01'))))
Friday, March 24, 2006
ROW_NUMBER, NTILE, RANK And DENSE_RANK
Yesterday I showed how to do ranking in SQL Server 2000, today we will look at how it's done in SQL Server 2005
CREATE TABLE Rankings (Value Char(1),id INT)
INSERT INTO Rankings
SELECT 'A',1 UNION ALL
SELECT 'A',3 UNION ALL
SELECT 'B',3 UNION ALL
SELECT 'B',4 UNION ALL
SELECT 'B',5 UNION ALL
SELECT 'C',2 UNION ALL
SELECT 'D',6 UNION ALL
SELECT 'E',6 UNION ALL
SELECT 'F',5 UNION ALL
SELECT 'F',9 UNION ALL
SELECT 'F',10
ROW_NUMBER()
This will just add a plain vanilla row number
SELECT ROW_NUMBER() OVER( ORDER BY Value ) AS 'rownumber',*
FROM Rankings
The following one is more interesting, besides the rownumber the Occurance field contains the row number count for a given value
That happens when you use PARTITION with ROW_NUMBER
SELECT ROW_NUMBER() OVER( ORDER BY value ) AS 'rownumber',
ROW_NUMBER() OVER(PARTITION BY value ORDER BY ID ) AS 'Occurance',*
FROM Rankings
ORDER BY 1,2
This is just ordered in alphabetical order descending
SELECT ROW_NUMBER() OVER( ORDER BY Value DESC) AS 'rownumber',*
FROM Rankings
RANK()
Rank will skip numbers if there are duplicate values
SELECT RANK() OVER ( ORDER BY Value),*
FROM Rankings
DENSE_RANK()
DENSE_RANK will not skip numbers if there are duplicate values
SELECT DENSE_RANK() OVER ( ORDER BY Value),*
FROM Rankings
NTILE()
NTILE splits the set in buckets
So for 11 values we do something like this: 11/2 =5 + 1 remainder, the first 6 rows get 1 the next 5 rows get 2
If we use NTILE(3) we would have something like this: 11/3 =3 + 2 remainders, so 3 buckets of 3 and the first 2 buckets will get 1 of the remainders each
SELECT NTILE(2) OVER ( ORDER BY Value ),*
FROM Rankings
SELECT NTILE(3) OVER ( ORDER BY Value ),*
FROM Rankings
CREATE TABLE Rankings (Value Char(1),id INT)
INSERT INTO Rankings
SELECT 'A',1 UNION ALL
SELECT 'A',3 UNION ALL
SELECT 'B',3 UNION ALL
SELECT 'B',4 UNION ALL
SELECT 'B',5 UNION ALL
SELECT 'C',2 UNION ALL
SELECT 'D',6 UNION ALL
SELECT 'E',6 UNION ALL
SELECT 'F',5 UNION ALL
SELECT 'F',9 UNION ALL
SELECT 'F',10
ROW_NUMBER()
This will just add a plain vanilla row number
SELECT ROW_NUMBER() OVER( ORDER BY Value ) AS 'rownumber',*
FROM Rankings
The following one is more interesting, besides the rownumber the Occurance field contains the row number count for a given value
That happens when you use PARTITION with ROW_NUMBER
SELECT ROW_NUMBER() OVER( ORDER BY value ) AS 'rownumber',
ROW_NUMBER() OVER(PARTITION BY value ORDER BY ID ) AS 'Occurance',*
FROM Rankings
ORDER BY 1,2
This is just ordered in alphabetical order descending
SELECT ROW_NUMBER() OVER( ORDER BY Value DESC) AS 'rownumber',*
FROM Rankings
RANK()
Rank will skip numbers if there are duplicate values
SELECT RANK() OVER ( ORDER BY Value),*
FROM Rankings
DENSE_RANK()
DENSE_RANK will not skip numbers if there are duplicate values
SELECT DENSE_RANK() OVER ( ORDER BY Value),*
FROM Rankings
NTILE()
NTILE splits the set in buckets
So for 11 values we do something like this: 11/2 =5 + 1 remainder, the first 6 rows get 1 the next 5 rows get 2
If we use NTILE(3) we would have something like this: 11/3 =3 + 2 remainders, so 3 buckets of 3 and the first 2 buckets will get 1 of the remainders each
SELECT NTILE(2) OVER ( ORDER BY Value ),*
FROM Rankings
SELECT NTILE(3) OVER ( ORDER BY Value ),*
FROM Rankings
Thursday, March 23, 2006
Ranking In SQL Server 2000
SQL server 2005 has 4 new ranking/windowing functions
These functions are RANK(), DENSE_RANK(), NTILE() and ROW_NUMBER()
I will show you tomorrow how you can use these new functions, today I will show you all the hard work you have to do to accomplish the same in SQL Server 2000
I am only going to show how to implement RANK(), DENSE_RANK() and ROW_NUMBER() in SQL Server 2000
CREATE TABLE Rankings (Value Char(1))
INSERT INTO Rankings
SELECT 'A' UNION ALL
SELECT 'A' UNION ALL
SELECT 'B' UNION ALL
SELECT 'B' UNION ALL
SELECT 'B' UNION ALL
SELECT 'C' UNION ALL
SELECT 'D' UNION ALL
SELECT 'E' UNION ALL
SELECT 'F' UNION ALL
SELECT 'F' UNION ALL
SELECT 'F'
So let's start with ROW_NUMBER()
Since we have duplicates we can't do a running count, we will use that for DENSE_RANK
Duplicates are not considered each row has a unique number
ROW_NUMBER()
SELECT IDENTITY(INT, 1,1) AS Rank ,Value
INTO #Ranks FROM Rankings WHERE 1=0
INSERT INTO #Ranks
SELECT Value FROM Rankings
ORDER BY Value
SELECT * FROM #Ranks
Next up is DENSE_RANK()
Duplicates are considered and same values have the same number, numbers are not skipped
DENSE_RANK()
SELECT x.Ranking ,x.Value
FROM (SELECT (SELECT COUNT( DISTINCT t1.Value) FROM Rankings t1 WHERE z.Value>= t1.Value)AS Ranking, z.Value
FROM #Ranks z ) x
ORDER BY x.Ranking
And last we have RANK()
Duplicates are considered and same values have the same number, however numbers are skipped
RANK()
SELECT z.Ranking ,t2.Value
FROM (SELECT MIN(t1.Rank) AS Ranking,t1.Value FROM #Ranks t1 GROUP BY t1.Value) z
JOIN #Ranks t2 ON z.Value = t2.Value
ORDER BY z.Ranking
That is it, tomorrow I will do the SQL Server 2005 version of this code
These functions are RANK(), DENSE_RANK(), NTILE() and ROW_NUMBER()
I will show you tomorrow how you can use these new functions, today I will show you all the hard work you have to do to accomplish the same in SQL Server 2000
I am only going to show how to implement RANK(), DENSE_RANK() and ROW_NUMBER() in SQL Server 2000
CREATE TABLE Rankings (Value Char(1))
INSERT INTO Rankings
SELECT 'A' UNION ALL
SELECT 'A' UNION ALL
SELECT 'B' UNION ALL
SELECT 'B' UNION ALL
SELECT 'B' UNION ALL
SELECT 'C' UNION ALL
SELECT 'D' UNION ALL
SELECT 'E' UNION ALL
SELECT 'F' UNION ALL
SELECT 'F' UNION ALL
SELECT 'F'
So let's start with ROW_NUMBER()
Since we have duplicates we can't do a running count, we will use that for DENSE_RANK
Duplicates are not considered each row has a unique number
ROW_NUMBER()
SELECT IDENTITY(INT, 1,1) AS Rank ,Value
INTO #Ranks FROM Rankings WHERE 1=0
INSERT INTO #Ranks
SELECT Value FROM Rankings
ORDER BY Value
SELECT * FROM #Ranks
Next up is DENSE_RANK()
Duplicates are considered and same values have the same number, numbers are not skipped
DENSE_RANK()
SELECT x.Ranking ,x.Value
FROM (SELECT (SELECT COUNT( DISTINCT t1.Value) FROM Rankings t1 WHERE z.Value>= t1.Value)AS Ranking, z.Value
FROM #Ranks z ) x
ORDER BY x.Ranking
And last we have RANK()
Duplicates are considered and same values have the same number, however numbers are skipped
RANK()
SELECT z.Ranking ,t2.Value
FROM (SELECT MIN(t1.Rank) AS Ranking,t1.Value FROM #Ranks t1 GROUP BY t1.Value) z
JOIN #Ranks t2 ON z.Value = t2.Value
ORDER BY z.Ranking
That is it, tomorrow I will do the SQL Server 2005 version of this code
Tuesday, March 21, 2006
Microsoft SQL Server 2005 Jolt Winner
Microsoft SQL Server 2005 is the Jolt Product Excellence and Productivity Award winner for database engines and data tools
DATABASE ENGINES AND DATA TOOLS
--------------------------------------------------
Jolt Winner: Microsoft SQL Server 2005 (Microsoft)
Productivity Winners:
• Berkeley DB 4.4 (Sleepycat Software)
• Google Maps API 2005 (Google)
• MySQL 5.0 (MySQL)
The rest of the categories are here
DATABASE ENGINES AND DATA TOOLS
--------------------------------------------------
Jolt Winner: Microsoft SQL Server 2005 (Microsoft)
Productivity Winners:
• Berkeley DB 4.4 (Sleepycat Software)
• Google Maps API 2005 (Google)
• MySQL 5.0 (MySQL)
The rest of the categories are here
Monday, March 20, 2006
Programming SQL Server 2005 Book
 I have just ordered this book without reading a sample chapter. I have about 15 O'Reilly books and all of them are excellent, that's why I did not hesitate purchasing this book. Once it arrives I will let you know more about it
I have just ordered this book without reading a sample chapter. I have about 15 O'Reilly books and all of them are excellent, that's why I did not hesitate purchasing this book. Once it arrives I will let you know more about itThis information is from the O'Reilly site:
SQL Server 2005, Microsoft's next-generation data management and analysis solution, represents a huge leap forward. It comes with a myriad of changes that deliver increased security, scalability, and power--making it the complete data package. Used properly, SQL Server 2005 can help organizations of all sizes meet their data challenges head on.
Programming SQL Server 2005 from O'Reilly provides a practical look at this updated version of Microsoft's premier database product. It guides you through all the new features, explaining how they work and how to use them. The first half of the book examines the changes and new features of the SQL Server Engine itself. The second addresses the enhanced features and tools of the platform, including the new services blended into this popular version. Each chapter contains numerous code samples-written in C# and compiled using the Visual Studio 2005 development environment-that show you exactly how to program SQL Server 2005.
Programming SQL Server 2005 can help you:
Build, deploy, and manage enterprise applications that are more secure, scalable, and reliable
Maximize IT productivity by reducing the complexity of building, deploying, and managing database applications
Share data across multiple platforms, applications, and devices to make it easier to connect internal and external systems
Because the goal of Programming SQL Server 2005 is to introduce all facets of Programming SQL Server 2005, it's beneficial to programmers of all levels. The book can be used as a primer by developers with little or no experience with SQL Server, as a ramp up to the new programming models for SQL Server 2005 for more experienced programmers, or as background and primer to specific concepts.
Any IT professional who wants to learn about SQL Server 2005's comprehensive feature set, interoperability with existing systems, and automation of routine tasks will find the answers in this authoritative guide.
Sample Chapter 18: Notification Services is available now
Amazon link is here
OPENROWSET And Open Excel file Problems
Last week I created a blog post name OPENROWSET And Excel Problems
I forgot to add one other example, and this is when you have an excel file open and you are trying to open it with OPENROWSET.
If you do this you will get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error. The provider did not give any information about the error.
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IDBInitialize::Initialize returned 0x80004005: The provider did not give any information about the error.].
Just keep this in mind
I forgot to add one other example, and this is when you have an excel file open and you are trying to open it with OPENROWSET.
If you do this you will get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error. The provider did not give any information about the error.
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IDBInitialize::Initialize returned 0x80004005: The provider did not give any information about the error.].
Just keep this in mind
Friday, March 17, 2006
SQL Server 2005 Service Pack 1 - Community Technology Preview (CTP)
The Community Technology Preview (CTP) version of Microsoft SQL Server 2005 Service Pack 1 is now available. You can use these packages to upgrade any of the following SQL Server 2005 editions:
Enterprise
Enterprise Evaluation
Developer
Standard
Workgroup
To upgrade SQL Server 2005 Express Edition, obtain the SP1 CTP version of Express Edition.
These packages have been made available for general testing purposes only. Do not deploy the CTP software in production
Click here to go to the download page
Enterprise
Enterprise Evaluation
Developer
Standard
Workgroup
To upgrade SQL Server 2005 Express Edition, obtain the SP1 CTP version of Express Edition.
These packages have been made available for general testing purposes only. Do not deploy the CTP software in production
Click here to go to the download page
Thursday, March 16, 2006
OPENROWSET And Excel Problems
Create an excel sheet
In the first 2 rows put some data, save the excel sheet as testing.xls on the c drive
Execute the command below
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing.xls','SELECT * FROM [Sheet1$]')
You will see 1 row since the first row will be used for header names
If you want 2 rows you need to add HDR=No like this
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing.xls;HDR=NO','SELECT * FROM [Sheet1$]')
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=SS:\testing.xls','SELECT * FROM [Sheet1$]')
The path can't be found (SS) you will get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error. The provider did not give any information about the error.
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IDBInitialize::Initialize returned 0x80004005: The provider did not give any information about the error.].
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing2.xls','SELECT * FROM [Sheet1$]')
When you spell the filename (testing2) wrong you get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error.
[OLE/DB provider returned message: The Microsoft Jet database engine could not find the object 'Sheet1$'. Make sure the object exists and that you spell its name and the path name correctly.]
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IColumnsInfo::GetColumnsInfo returned 0x80004005: ].
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing.xls','SELECT * FROM [Sheet11$]')
When you spell the sheet name (Sheet11) wrong you get this error
Server: Msg 7357, Level 16, State 2, Line 1
Could not process object 'Select * from [Sheet11$]'. The OLE DB provider 'Microsoft.Jet.OLEDB.4.0' indicates that the object has no columns.
OLE DB error trace [Non-interface error: OLE DB provider unable to process object, since the object has no columnsProviderName='Microsoft.Jet.OLEDB.4.0', Query=Select * from [P2 2003 DJIA updates$]'].
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=D:\testing.xls','SELECT * FROM [Sheet1$]')
When you type the wrong path (D) but the path exists, then you get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error. The provider did not give any information about the error.
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IDBInitialize::Initialize returned 0x80004005: The provider did not give any information about the error.].
So hopefully the next time you get an error you can quickly figure out if it's the file name, sheet name or path name that is wrong
In the first 2 rows put some data, save the excel sheet as testing.xls on the c drive
Execute the command below
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing.xls','SELECT * FROM [Sheet1$]')
You will see 1 row since the first row will be used for header names
If you want 2 rows you need to add HDR=No like this
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing.xls;HDR=NO','SELECT * FROM [Sheet1$]')
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=SS:\testing.xls','SELECT * FROM [Sheet1$]')
The path can't be found (SS) you will get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error. The provider did not give any information about the error.
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IDBInitialize::Initialize returned 0x80004005: The provider did not give any information about the error.].
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing2.xls','SELECT * FROM [Sheet1$]')
When you spell the filename (testing2) wrong you get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error.
[OLE/DB provider returned message: The Microsoft Jet database engine could not find the object 'Sheet1$'. Make sure the object exists and that you spell its name and the path name correctly.]
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IColumnsInfo::GetColumnsInfo returned 0x80004005: ].
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=C:\testing.xls','SELECT * FROM [Sheet11$]')
When you spell the sheet name (Sheet11) wrong you get this error
Server: Msg 7357, Level 16, State 2, Line 1
Could not process object 'Select * from [Sheet11$]'. The OLE DB provider 'Microsoft.Jet.OLEDB.4.0' indicates that the object has no columns.
OLE DB error trace [Non-interface error: OLE DB provider unable to process object, since the object has no columnsProviderName='Microsoft.Jet.OLEDB.4.0', Query=Select * from [P2 2003 DJIA updates$]'].
Run the following OPENROWSET command
SELECT * FROM OPENROWSET( 'Microsoft.Jet.OLEDB.4.0',
'Excel 8.0;Database=D:\testing.xls','SELECT * FROM [Sheet1$]')
When you type the wrong path (D) but the path exists, then you get this error
Server: Msg 7399, Level 16, State 1, Line 1
OLE DB provider 'Microsoft.Jet.OLEDB.4.0' reported an error. The provider did not give any information about the error.
OLE DB error trace [OLE/DB Provider 'Microsoft.Jet.OLEDB.4.0' IDBInitialize::Initialize returned 0x80004005: The provider did not give any information about the error.].
So hopefully the next time you get an error you can quickly figure out if it's the file name, sheet name or path name that is wrong
Tuesday, March 14, 2006
Find Out If A Table Has An Identity Column
Here are 2 ways to find out if a table has an identity column
The first way is using the COLUMNPROPERTY function and the second way is using the OBJECTPROPERTY function
USE northwind
GO
DECLARE @tableName VARCHAR(50)
SELECT @tableName = 'orders'
--Use COLUMNPROPERTY and the syscolumns system table
SELECT COUNT(name) AS HasIdentity
FROM syscolumns
WHERE OBJECT_NAME(id) = @tableName
AND COLUMNPROPERTY(id, name, 'IsIdentity') = 1
GO
DECLARE @intObjectID INT
SELECT @intObjectID =OBJECT_ID('orders')
--Use OBJECTPROPERTY and the TableHasIdentity property name
SELECT COALESCE(OBJECTPROPERTY(@intObjectID, 'TableHasIdentity'),0) AS HasIdentity
The first way is using the COLUMNPROPERTY function and the second way is using the OBJECTPROPERTY function
USE northwind
GO
DECLARE @tableName VARCHAR(50)
SELECT @tableName = 'orders'
--Use COLUMNPROPERTY and the syscolumns system table
SELECT COUNT(name) AS HasIdentity
FROM syscolumns
WHERE OBJECT_NAME(id) = @tableName
AND COLUMNPROPERTY(id, name, 'IsIdentity') = 1
GO
DECLARE @intObjectID INT
SELECT @intObjectID =OBJECT_ID('orders')
--Use OBJECTPROPERTY and the TableHasIdentity property name
SELECT COALESCE(OBJECTPROPERTY(@intObjectID, 'TableHasIdentity'),0) AS HasIdentity
Monday, March 13, 2006
Search All Stored Procedures That Contain Specific Text
You have changed the column name from titleauthor to t_author in your table and you have 200 stored procedures
The problem is that you don't remember which of these 200 procedures use that column
You run sp_depends 'authors' but like we all know this procedure is not always accurate
So instead of running sp_depends we can take a look at the INFORMATION_SCHEMA.ROUTINES ANSI SQL Schema view
Let's search for all procedures that have the text titleauthor in them
USE pubs
GO
SELECT SPECIFIC_NAME,*
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE ='PROCEDURE'
AND ROUTINE_DEFINITION LIKE '%titleauthor%'
The problem is that you don't remember which of these 200 procedures use that column
You run sp_depends 'authors' but like we all know this procedure is not always accurate
So instead of running sp_depends we can take a look at the INFORMATION_SCHEMA.ROUTINES ANSI SQL Schema view
Let's search for all procedures that have the text titleauthor in them
USE pubs
GO
SELECT SPECIFIC_NAME,*
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE ='PROCEDURE'
AND ROUTINE_DEFINITION LIKE '%titleauthor%'
Thursday, March 09, 2006
Create Stored Procedures With Optional Parameters
Sometimes you want to create stored procedures in which all the parameters are not required or will be used. You can create optional parameters and give them a value in the procedure. There are two ways to call procedures; you can pass parameters to stored procedures by name or by position. To pass parameters by name you would do something like this
EXEC prTestOptionalParameters @intID =1
To pass parameters by position you would do something like this
EXEC prTestOptionalParameters 1
Just keep in mind that if you pass by position that you don’t mix up the position because that makes for fun debugging time. Another problem with optional parameters is that if you call the procedure by using position for parameters then those parameters have to be at the end of the procedure. Let’s take a look at how this works
--Create the procedure with optional parameters at the end
CREATE PROCEDURE prTestOptionalParameters
@intID INT,
@chvName VARCHAR(80) = NULL
AS
SET NOCOUNT ON
IF @chvName IS NULL
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is null' AS message
END
ELSE
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is not null' AS message
END
SET NOCOUNT OFF
--Run the proc without the optional parameter
EXEC prTestOptionalParameters 1
--Run the proc with the second parameter
EXEC prTestOptionalParameters 1,'abc'
--Run the proc without the optional parameter and use name parameters
EXEC prTestOptionalParameters @intID =1
--Run the proc with a null value for the optional parameter
EXEC prTestOptionalParameters 1 ,null
--Let's switch the parameters around
CREATE PROCEDURE prTestOptionalParameters2
@chvName VARCHAR(80) = NULL,
@intID INT
AS
SET NOCOUNT ON
IF @chvName IS NULL
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is null' AS message
END
ELSE
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is not null' AS message
END
SET NOCOUNT OFF
--Run the proc without the optional parameter
EXEC prTestOptionalParameters2 1
You will get this error message
Server: Msg 201, Level 16, State 4, Procedure prTestOptionalParameters2, Line 0Procedure 'prTestOptionalParameters2' expects parameter '@intID', which was not supplied.
--Run the procedure with the named parameter
EXEC prTestOptionalParameters2 @intID =1
EXEC prTestOptionalParameters @intID =1
To pass parameters by position you would do something like this
EXEC prTestOptionalParameters 1
Just keep in mind that if you pass by position that you don’t mix up the position because that makes for fun debugging time. Another problem with optional parameters is that if you call the procedure by using position for parameters then those parameters have to be at the end of the procedure. Let’s take a look at how this works
--Create the procedure with optional parameters at the end
CREATE PROCEDURE prTestOptionalParameters
@intID INT,
@chvName VARCHAR(80) = NULL
AS
SET NOCOUNT ON
IF @chvName IS NULL
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is null' AS message
END
ELSE
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is not null' AS message
END
SET NOCOUNT OFF
--Run the proc without the optional parameter
EXEC prTestOptionalParameters 1
--Run the proc with the second parameter
EXEC prTestOptionalParameters 1,'abc'
--Run the proc without the optional parameter and use name parameters
EXEC prTestOptionalParameters @intID =1
--Run the proc with a null value for the optional parameter
EXEC prTestOptionalParameters 1 ,null
--Let's switch the parameters around
CREATE PROCEDURE prTestOptionalParameters2
@chvName VARCHAR(80) = NULL,
@intID INT
AS
SET NOCOUNT ON
IF @chvName IS NULL
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is null' AS message
END
ELSE
BEGIN
SELECT @intID AS ID, @chvName AS Name,'@chvName is not null' AS message
END
SET NOCOUNT OFF
--Run the proc without the optional parameter
EXEC prTestOptionalParameters2 1
You will get this error message
Server: Msg 201, Level 16, State 4, Procedure prTestOptionalParameters2, Line 0Procedure 'prTestOptionalParameters2' expects parameter '@intID', which was not supplied.
--Run the procedure with the named parameter
EXEC prTestOptionalParameters2 @intID =1
Wednesday, March 08, 2006
Create Procedures That Run At SQL Server Startup
Let's say you have a table and you want to make sure that you clear it every time SQL Server is restarted
What would be the easiest way to accomplish that? Well you can create a procedure and have it execute every time the SQL Server is restarted
The procedure has to be created in the master database, after it is created you have to use sp_procoption to have the procedure execute when SQL Server starts up
--Let's create our procedure
USE master
GO
CREATE PROCEDURE prStartUp
AS
SELECT GETDATE()
--You would do something real here
--like deleting the data
GO
--Make the procedure execute when the server starts up
sp_procoption prStartUp,startup,'on'
--This will return the proc name since we enabled the ExecIsStartup property
SELECT name FROM sysobjects
WHERE xtype = 'p'
AND OBJECTPROPERTY(id, 'ExecIsStartup') = 1
--disable the execution of the proc on start up
sp_procoption prStartUp,startup,'off'
--Let's check again, no rows should be returned now
SELECT name FROM sysobjects
WHERE xtype = 'p'
AND OBJECTPROPERTY(id, 'ExecIsStartup') = 1
What would be the easiest way to accomplish that? Well you can create a procedure and have it execute every time the SQL Server is restarted
The procedure has to be created in the master database, after it is created you have to use sp_procoption to have the procedure execute when SQL Server starts up
--Let's create our procedure
USE master
GO
CREATE PROCEDURE prStartUp
AS
SELECT GETDATE()
--You would do something real here
--like deleting the data
GO
--Make the procedure execute when the server starts up
sp_procoption prStartUp,startup,'on'
--This will return the proc name since we enabled the ExecIsStartup property
SELECT name FROM sysobjects
WHERE xtype = 'p'
AND OBJECTPROPERTY(id, 'ExecIsStartup') = 1
--disable the execution of the proc on start up
sp_procoption prStartUp,startup,'off'
--Let's check again, no rows should be returned now
SELECT name FROM sysobjects
WHERE xtype = 'p'
AND OBJECTPROPERTY(id, 'ExecIsStartup') = 1
Monday, March 06, 2006
Returning Grouped Random Results
Let's say you have data and you want to return this random but grouped, what do I mean by that? For example you have the following data
sony 4
sony 6
toshiba 1
toshiba 3
mitsubishi 2
mitsubishi 5
When you rerun the query you want the order to be different but the companies have to be grouped together. So the next result could be something like this
toshiba 1
toshiba 3
sony 4
sony 6
mitsubishi 2
mitsubishi 5
To order a result set randomly every single time is easy you just have to add ORDER BY NEWID() and it will be different every single time
To order randomly and keeping it 'ordered/grouped' by company is a little bit trickier
Below are 2 ways to accomplish that. The first way is with a sub query the second is by using RAND and CHECKSUM
If you run the two queries at the same time and look at the execution plan you will notice that the query cost for the query with the sub query is 66.75% (relative to the batch) and for the query with RAND and CHECKSUM it's only 33.25%
For those of you who don't know how to see the execution plan, this is how you do that
CTRL + K (you can also select Query-->Show Execution Plan from the menu bar) then highlight both queries and press F5. Between Grids and Messages you will see a new tab named Execution Plan, click on that tab and you will see a graphical representation of the execution plan
CREATE TABLE #Testcompanies (
Name VARCHAR(50),
ID INT)
INSERT INTO #Testcompanies
SELECT 'toshiba' ,1
UNION ALL
SELECT 'mitsubishi', 2
UNION ALL
SELECT 'toshiba', 3
UNION ALL
SELECT 'sony', 4
UNION ALL
SELECT 'mitsubishi', 5
UNION ALL
SELECT 'sony', 6
--Query using a sub query and NEWID()
SELECT T.*
FROM #Testcompanies T
JOIN (SELECT DISTINCT TOP 100 PERCENT Name,
NEWID() AS GroupedOrder
FROM #Testcompanies
GROUP BY Name
ORDER BY NEWID()) Z
ON T.Name = Z.Name
ORDER BY Z.GroupedOrder
--Query using RAND()
DECLARE @R FLOAT
SET @R = RAND()
SELECT TOP 100 PERCENT *
FROM #TESTCOMPANIES
ORDER BY RAND(@R * CHECKSUM(NAME))
sony 4
sony 6
toshiba 1
toshiba 3
mitsubishi 2
mitsubishi 5
When you rerun the query you want the order to be different but the companies have to be grouped together. So the next result could be something like this
toshiba 1
toshiba 3
sony 4
sony 6
mitsubishi 2
mitsubishi 5
To order a result set randomly every single time is easy you just have to add ORDER BY NEWID() and it will be different every single time
To order randomly and keeping it 'ordered/grouped' by company is a little bit trickier
Below are 2 ways to accomplish that. The first way is with a sub query the second is by using RAND and CHECKSUM
If you run the two queries at the same time and look at the execution plan you will notice that the query cost for the query with the sub query is 66.75% (relative to the batch) and for the query with RAND and CHECKSUM it's only 33.25%
For those of you who don't know how to see the execution plan, this is how you do that
CTRL + K (you can also select Query-->Show Execution Plan from the menu bar) then highlight both queries and press F5. Between Grids and Messages you will see a new tab named Execution Plan, click on that tab and you will see a graphical representation of the execution plan
CREATE TABLE #Testcompanies (
Name VARCHAR(50),
ID INT)
INSERT INTO #Testcompanies
SELECT 'toshiba' ,1
UNION ALL
SELECT 'mitsubishi', 2
UNION ALL
SELECT 'toshiba', 3
UNION ALL
SELECT 'sony', 4
UNION ALL
SELECT 'mitsubishi', 5
UNION ALL
SELECT 'sony', 6
--Query using a sub query and NEWID()
SELECT T.*
FROM #Testcompanies T
JOIN (SELECT DISTINCT TOP 100 PERCENT Name,
NEWID() AS GroupedOrder
FROM #Testcompanies
GROUP BY Name
ORDER BY NEWID()) Z
ON T.Name = Z.Name
ORDER BY Z.GroupedOrder
--Query using RAND()
DECLARE @R FLOAT
SET @R = RAND()
SELECT TOP 100 PERCENT *
FROM #TESTCOMPANIES
ORDER BY RAND(@R * CHECKSUM(NAME))
Conversation With Database Legend Jim Gray
 Channel 9 has an interesting video with Turing award winner Jim Gray. From the website: "This episode features Jim Gray. He is a "Technical Fellow" in the Scaleable Servers Research Group (Sky Server, Terra Server) and manager of Microsoft's Bay Area Research Center (BARC). Jim has been called a "giant" in the fields of database and transaction processing computer systems. In 1998, Jim was awarded the ACM’s prestigious A.M. Turing Award.
Channel 9 has an interesting video with Turing award winner Jim Gray. From the website: "This episode features Jim Gray. He is a "Technical Fellow" in the Scaleable Servers Research Group (Sky Server, Terra Server) and manager of Microsoft's Bay Area Research Center (BARC). Jim has been called a "giant" in the fields of database and transaction processing computer systems. In 1998, Jim was awarded the ACM’s prestigious A.M. Turing Award. Before joining Microsoft, Jim worked at Digital Equipment Corp (DEC)., Tandem Computers Inc., IBM Corp. and AT&T and he is the editor of the “Performance Handbook for Database and Transaction Processing Systems,” and co-author of “Transaction Processing: Concepts and Techniques.” In this interview, Jim is joined by former colleague from DEC and partner on the Terra Server project, Researcher, Tom Barclay."
Pro SQL Server 2005 Assemblies
 Pro SQL Server 2005 Assemblies provides a detailed and example-driven tutorial on how to build and use .NET assemblies. The authors focus on building assemblies in C#, but also provide the equivalent VB .NET code in the supplied code download.
Pro SQL Server 2005 Assemblies provides a detailed and example-driven tutorial on how to build and use .NET assemblies. The authors focus on building assemblies in C#, but also provide the equivalent VB .NET code in the supplied code download.Assemblies are not a complete replacement for T-SQL stored procedures and triggers; rather, they’re enhancements, to be used at the right place and right time. This book examines the ins and outs of assemblies—when they should and should not be used, what you can do with them, and how you can get the most out of them.
Table Of Contents
CHAPTER 1 Introducing Assemblies
CHAPTER 2 Writing a Simple SQL Assembly
CHAPTER 3 The SQL Server NET Programming Model
CHAPTER 4 CLR Stored Procedures
CHAPTER 5 User-Defined Functions
CHAPTER 6 User-Defined Types
CHAPTER 7 User-Defined Aggregates
CHAPTER 8 CLR Triggers
CHAPTER 9 Error Handling and Debugging Strategies
CHAPTER 10 Security
CHAPTER 11 Integrating Assemblies with Other Technologies
INDEX
Sample Chapter: The SQL Server NET Programming Model
Amazon link here
Subscribe to:
Comments (Atom)